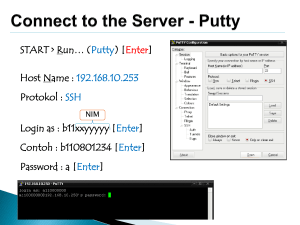
contoh kasus dalam riset skripsi dan tesis dengan regresi linier
advertisement

CONTOH KASUS DALAM RISET SKRIPSI DAN TESIS DENGAN REGRESI LINIER OLEH: JONATHAN SARWONO 12-01-2017 Kasus Pertama Sebuah perusahaan melakukan penelitian dengan tujuan ingin mengetahui apakah Variabel Jumlah tenaga kerja berpengaruh terhadap Variabel Biaya produksi tidak langsung serta untuk mengetahui apakah biaya tersebut dapat diprediksi dengan menggunakan variabel jumlah tenaga kerja? Penelitian ini menggunakan data selama dua belas bulan. Data seperti terlihat di bawah ini: Bulan Januari Februari Maret April Mei Juni Juli Agustus September Oktober November Desember Biaya Produksi Tidak Langsung 200 140 130 175 240 120 160 90 300 89 70 60 Jumlah Tenaga Kerja 30 25 15 24 31 27 10 9 29 12 16 14 Adapun rumusan masalahnya sebagai berikut: Berapa besar pengaruh variabel jumlah tenaga kerja terhadap biaya produksi tidak langsung? Bagaimana kecenderungan biaya produksi tidak langsung di waktu yang akan datang? Penyelesaian Jika dilihat dari model hubungan variabel tersebut di atas, maka kita dapat melakukan identifikasi sebagai berikut: Variabel jumlah tenaga kerja merupakan variabel bebas atau independen dan juga disebut sebagai variabel predictor. Variabel biaya produksi tidak langsung merupakan variabel tergantung atau dependen. Bulan merupakan label kasus yang dalam SPSS disebut sebagai Case Label. Untuk menyelesaikan masalah ini kita akan menggunakan prosedur Regresi Linier Sederhana yang cocok dengan masalah dalam penelitian tersebut. Konsep Dasar Regresi Linier Regresi linier merupakan model persamaan yang didasarkan pada garis lurus yang mencerminkan adanya hubungan linier antara variabel bebas (X) dengan variabel tergantung (Y). Garis lurus tersebut dapat didefinisikan dengan dua hal, yaitu: pertama, slope atau gradient yang diwakili dengan notasi β1 dan kedua, suatu titik dimana garis melintasi sumbu vertikal dalam grafik yang disebut sebagai intercept dan diwakili dengan notasi a atau β0. Dalam buku ini digunakan notasi “a”. Dengan demikian kita akan membuat model dengan menggunakan data yang kita miliki untuk disesuaikan dengan model garis lurus yang mencerminkan hubungan linier antara variabel Jumlah tenaga kerja dengan variabel Biaya produksi. Untuk memahami regresi linier dengan benar kita akan melihat gambar garis regresi seperti di bawah ini. Persamaannya ialah : Y = a + β1X1 Dengan: Y= variabel tergantung / variabel kriteria (Dalam SPSS disebut dependen variable) a= intercept Y (Dalam SPSS disebut konstan) β = kemiringan (disebut juga slope atau gradient dan dalam SPSS disebut koefesien regresi) X= variabel bebas (Dalam SPSS disebut independen variable) Persamaan Dalam Regresi Linier Sederhana Regresi linier mempunyai persamaan yang disebut sebagai persamaan regresi. Persamaan regresi mengekspresikan hubungan linier antara variabel tergantung / variabel kriteria yang diberi simbol Y dan salah satu atau lebih variabel bebas / prediktor yang diberi simbol X jika hanya ada satu prediktor dan X1, X2 sampai dengan Xk, jika terdapat lebih dari satu prediktor (Crammer & Howitt, 2006:139). Persamaan regresi akan terlihat seperti di bawah ini: Untuk persamaan regresi dimana Y merupakan nilai yang diprediksi, maka persamaannya ialah Y = a + β1X1 (untuk regresi linier sederhana) Y = a + β1X1 + β2X2 + … + βkXk (untuk regresi linier berganda) Untuk persamaan regresi dimana Y merupakan nilai sebenarnya (observasi), maka persamaan menyertakan kesalahan (error term / residual) akan menjadi: Y = a + β1X1 + e (untuk regresi linier sederhana) Y = a + β1X1 + β2X2 + … + βkXk + e (untuk regresi linier berganda) Dimana: X: merupakan nilai sebenarnya suatu kasus (data) pada variabel bebas (X) β: merupakan koefesien regresi jika hanya ada satu prediktor dan koefesien regresi parsial jika terdapat lebih dari satu prediktor. Nilai ini juga mewakili mewakili koefesien regresi baku (standardized) dan koefesien regresi tidak baku (unstandardized). Koefesien regresi ini merupakan jumlah perubahan yang terjadi pada Y yang disebabkan oleh perubahan nilai X. Untuk menghitung perubahan ini dapat dilakukan dengan cara mengkalikan nilai prediktor sebenarnya (observasi) untuk kasus (data) tertentu dengan koefesien regresi prediktor tersebut. a: merupakan intercept yang merupakan nilai Y saat nilai prediktor (variabel bebas) sebesar nol (X = 0) Hubungan Linier dalam Regresi Linier Garis regresi mempunyai 3 (tiga) kemungkinan yaitu: 1) hubungan linier positif, 2) hubungan linier negatif, dan 3) tidak ada hubungan linier. 1. hubungan linier positif 2. Hubungan Linier Negatif 3. tidak ada hubungan linier Istilah Variabel dalam Regresi Linier Agar kita memperoleh kejelasan dalam penggunaan istilah, maka di bawah ini diberikan istilah-istilah yang mewakili pengertian variabel bebas dan variabel tergantung dalam regresi. Gujarati memberikan istilah sebagai berikut: Variabel tergantung (dependent variable): disebut juga sebagai variabel yang dijelaskan (explained variable) / variabel yang diprediksi (predictand) / regresan (regressand) / variabel yang merespon ( response) / endegenous / keluaran (outcome) / variabel yang dikontrol (controlled variable). Variabel yang menerangkan (explanatory variable): disebut juga sebagai variabel bebas (independent variable) / variabel yang memprediksi (predictor) / regresor (regressor) / variabel stimulus ( stimulus) / exogenous / kovariat (covariate) / variabel kontrol (control variable). Metode Least Square dalam Regresi Linier Regresi linier menggunakan metode Least Square yang merupakan suatu cara untuk menemukan garis yang paling cocok dengan data yang kita miliki. Garis yang paling cocok ini dapat diperoleh dengan cara menemukan garis mana saja dari garis – garis yang dapat digambarkan, yang menghasilkan jumlah perbedaan terkecil antara titik – titik data observasi dengan garis tersebut. Untuk memudahkan memahami uraian ini pada gambar berikut ini ditunjukkan ketika garis tertentu sesuai atau cocok dengan data; maka akan perbedaan kecil antara nilai – nilai yang diprediksi oleh garis dengan data yang dihasilkan dari observasi (riset). Perbedaan tersebut dapat bersifat positif dimana titik-titik sebaran data berada di atas garis yang menunjukkan dimana model yang kita buat gagal memahami (underestimate) nilai – nilai sebaran data. Sedang perbedaan yang bersifat negatif dimana titik-titik sebaran data berada di bawah garis yang menunjukkan dimana model yang kita terlalu melebihlebihkan (overestimate) nilai – nilai sebaran datanya. Perbedaan tersebut dalam regresi linier disebut sebagai residual (selisih antara nilai prediksi dengan nilai observasi). Untuk model yang baik nilai residual harus semakin kecil yang digambarkan dengan sebaran data yang semakin dekat dengan garis lurus. Dengan kata lain jika titik – titik sebaran data baik yang diatas maupun dibawah garis lurus semakin menempel dekat dengan garis lurus menunjukkan nilai residual yang semakin kecil yang pada akhirnya menunjukkan model yang semakin benar. Apabila kita menjumlahkan perbedaan – perbedaan positif dan negatif maka akan ada kecenderungan saling menghilangkan. Untuk menghindari kasus ini maka sebelum menjumlahkan perbedaan – perbedaan tersebut, maka kita harus mengkuadratkan perbedaan – perbedaan tersebut terlebih dahulu. Perbedaan – perbedaan yang sudah dikuadratkan tersebut akan memberikan sarana kalkulasi seberapa baik garis tertentu cocok dengan data. Apabila perbedaan yang dikuadratkan tersebut besar, maka garis akan tidak cocok dengan data atau tidak mewakili data; sebaliknya jika perbedaan tersebut kecil maka garis tersebut akan cocok dengan data atau tidak mewakili data. Jumlah perbedaan yang dikuadratkan (sum of squared differences (SS)) dapat dihitung untuk setiap garis yang cocok dengan data tertentu. Kecocokan (Goodness of Fit) untuk setiap garis dapat dibandingkan dengan cara melihat nilai SS masing-masing. Metode Least Square bekerja dengan cara memilih garis yang mempunyai nilai jumlah perbedaan yang dikuadratkan (sum of square (SS)) terkecil. Dengan kata lain, metode ini memilih garis-garis yang paling baik (cocok) untuk mewakili data observasi. Dengan demikian cara yang terbaik ialah dengan menghitung nilai SS untuk setiap garis sampai mendapatkan garis yang mempunyai nilai SS terkecil. Sebaran data dengan garis yang mewakili kecenderungan umum Pada gambar di atas menunjukkan sebaran data dengan garis dimana sebaran data tersebut membentuk garis lurus sebagaimana garis kecenderungan umum (garis lurus dari kiri bawah ke kanan atas yang menunjukkan hubungan linier antara variabel X dan Y). Bulatan-bulatan menggambarkan sebaran data, garis miring menggambarkan garis lurus yang menunjukkan hubungan linier antara X dan Y sedang garis vertikal potong-potong menunjukkan nilai perbedaan atau residual antara garis dengan data sebenarnya. Pengujian kelayakan model dalam regresi dapat dilakukan dengan menggunakan Kelayakan Model Regresi Linier Sederhana Ditinjau dengan Pendekatan Nilai R dan R2 Apakah model regresi yang dibuat berdasarkan data observasi yang kita miliki sudah benar? Jawabannya adalah dengan melihat nilai R dan R2 . Nilai R2 merupakan nilai yang diperoleh dari jumlah kuadrat model regresi (sum of squares of the model) dibagi dengan jumlah total kuadrat (total sum of squares). Rumusnya seperti di bawah ini. R2= 𝑆𝑆𝑟𝑒𝑔 𝑆𝑆𝑡𝑜𝑡𝑎𝑙 =1- 𝑆𝑆𝑟𝑒𝑠 𝑆𝑆𝑡𝑜𝑡𝑎𝑙 Dimana: SSreg= nilai sum of square dari model regresi SStotal= SSy = nilai sum of square total SSres= nilai sum of square residual Hasil dari penghitungan R2 ini dapat dipersenkan dengan cara mengkalikan 100 yang kemudian disebut sebagai Koefesien Determinasi yang menyatakan jumlah persentase varian variabel tergantung yang dapat dijelaskan oleh model regresi yang kita buat. Jika nilai R2 ini diakarkan kita akan memperoleh nilai Koefesien Korelasi Pearson (R). Dengan demikian dalam regresi linier sederhana nilai R memberikan estimasi yang baik untuk kecocokan keseluruhan model regresi dan R2 memberikan penilaian yang baik untuk ukuran mendasar hubungan dua variabel yang kita regresikan (Field, 2006). Dengan bahasa yang mudah dapat kita katakan bahwa nilai koefesien korelasi Pearson (R) dapat digunakan sebagai indikator benar atau salahnya model regresi linier sederhana secara keseluruhan sedang nilai R2 mencerminkan kebenaran hubungan yang mendasar antara variabel bebas dan variabel tergantung yang kita regresikan. Kesimpulannya ialah jika nilai R semakin tinggi mendekati 1 (nilai maksimum R sebesar 1) maka model yang dibuat semakin benar dan nilai R2 semakin tinggi maka hubungan antara variabel bebas dan variabel tergantung semakin mendekati linier sempurna. Sekalipun demikian kita tidak dapat membuat kesimpulan kelayakan model semata-mata hanya menggunakan nilai R dan R2. Karena tujuan utama membuat model regresi linier bukan hanya mencari nilai R dan R2 yang tinggi tetapi ada tujuan yang lebih penting yaitu memprediksi parameter koefesien regresi (β) yang signifikan. Jika kita hanya melihat nilai R2 saja maka kita melihat kebenaran model regresi yang kita buat hanya dari sudut pandang linieritas hubungan dua variabel yang kita regresikan. Sebagaimana pendapat Gujarati (2009), dia mengatakan perlu diluruskan bahwa tujuan utama dalam prosedur analisis regresi linier bukan hanya semata-mata untuk memperoleh nilai R2 setinggi mungkin tetapi lebih ke hal dalam memperoleh estimasi koefesien regresi pada populasi yang sebenarnya melalui sampel yang kita teliti yang pada akhirnya nilai tersebut dapat digunakan untuk melakukan inferensi secara statistik. Jika saat kita melakukan riset diperoleh nilai R2 tinggi, hal tersebut merupakan salah satu petunjuk riset tersebut benar dan baik; sekalipun demikian dengan nilai R2 yang tidak tinggi sekalipun itu tidak berarti sama sekali bahwa hasil riset tersebut salah atau jelek. Oleh karena itu kita saat melakukan riset harus lebih fokus pada relevansi teoritis hubungan antara variabel-variabel bebas dengan variabel tergantungnya dan signifikansi hubungan tersebut secara statistik. Dengan menggunakan bahasa yang umum, sebaiknya kita lebih fokus untuk memperoleh hasil riset yang signifikan itu jauh lebih penting dibandingkan dengan memperoleh nilai R2 yang tinggi semata-mata. Hal ini ditegaskan pula oleh Goldberger (1998) dalam bukunya Introductory Econometrics sebagaimana dikutip oleh Gujarati (2009) yang mengatakan:”Sekalipun demikian nilai R2 yang tinggi bukan bukti bahwa model itu benar; sebaliknya R2 yang rendah bukan berarti model salah. Kenyataannya hal yang paling penting dalam regresi linier adalah fokus pada parameter dalam populasi bukan kecocokan model dalam sampel.” Nilai Adjusted R square (𝑹2) dalam Regresi Linier Sederhana Adjusted R square (𝑹2): nilai R2 yang disesuaikan dengan mempertimbakan jumlah variabel bebas / predictor yang dimasukkan dalam persamaan regresi dan ukuran sampel. Asumsinya jika variabel bebas ditambahkan nilai ini cenderung naik. Nilai ini sering digunakan sebagai nilai kecocokan model (goodness of fit) dimana jika nilainya semakin tinggi (mendekati 1), model semakin benar / akurat. Nilai ini umumya lebih kecil dari nilai R square-nya meski kadang dapat juga sama (𝑹2 ≤ R2). Nilai ini hanya dapat naik jika nilai t absolut dari variabel yang ditambahkan lebih besar dari 1. Jika dibandingkan antara antara nilai R square dan nilai adjusted R square untuk pengukuran kecocokan model, maka nilai 𝑹2 akan lebih baik. Untuk menghasilkan perbandingan yang valid diperlukan variabel tergantung yang sama. Rumus untuk nilai ini ialah: 𝑹2 = 1 – 𝑆𝑆𝑟𝑒𝑠/(𝑛−𝑘) 𝑆𝑆𝑡𝑜𝑡𝑎𝑙/(𝑛−1) = 1 – (1 – R2) 𝑛−1 𝑛−𝑘 Dimana: SSres= nilai sum of square residual SStotal= SSy = nilai sum of square total n= jumlah sampel k= jumlah variable R2: nilai R square Nilai F dalam Regresi Linier Sederhana Nilai F terdapat dalam keluaran ANOVA merupakan nilai yang digunakan untuk melakukan pengujian hipotesis secara simultan. Pengujian ini dilakukan dengan cara membandingkan antara nilai F hitung (Fo) dengan F tabel (F nilai kritis) dengan menggunakan ketentuan, yaitu: jika nilai F hitung > F tabel dengan tingkat signifikansi (α) tertentu, misalnya sebesar 0,05 maka H0 ditolak dan H1 diterima; sebaliknya jika nilai F hitung < F tabel maka H0 diterima dan H1 ditolak. Untuk memperoleh nilai F digunakan formula seperti di bawah ini. F= 𝑺𝑺𝒓𝒆𝒈/(𝒌−𝟏) 𝑺𝑺𝒓𝒆𝒔/(𝒏−𝒌) Dimana: SSreg= nilai sum of square dari regresi SSres= nilai sum of square residual n= jumlah sampel k= jumlah variabel Jika dilihat dari rumus di atas, maka untuk memperoleh nilai F tinggi, maka kita memerlukan nilai residual yang kecil dan jumlah data yang besar serta jumlah variabel bebas (predictor) yang tidak banyak. Nilai residual akan kecil jika hubungan antara variabel bebas dan tergantung linier. Hubungan antara variabel bebas dan tergantung akan semakin linier jika data observasi yang kita peroleh dilapangan berdistribusi normal dan dalam jumlah yang memenuhi persyaratan, misalnya dengan tingkat keyakinan sebesar 95% data akan sebesar antara 300 – 400 dan dengan . tingkat keyakinan sebesar 90% data akan sebesar antara 98 – 100 Nilai F berbanding lurus dengan nilai R2, dengan demikian jika nilai R2 semakin besar, maka nilai F juga semakin besar. Sebaliknya jika nilai R2 semakin kecil, maka nilai F juga semakin kecil. Oleh karena itu kita dapat menyimpulkan bahwa pengujian hipotesis dengan nilai F tidak hanya berfungsi sebagai pengujian signifikansi keseluruhan regresi yang diestimasi, tetapi juga untuk pengujian signifikansi nilai R2. Dengan demikian untuk memperoleh nilai F selain menggunakan rumus di atas, kita dapat mendapatkannya dengan rumus: Nilai Koefesien Regresi (β) dalam Regresi Linier Sederhana Koefesien regresi yang diberi notasi β merupakan nilai statistik dalam regresi linier pokok yang mewakili gradient atau slope pada garis regresi. Nilai ini mengekspresikan perubahan pada variabel tergantung yang disebabkan oleh perubahan unit dalam prediktor atau variabel bebas. Koefesien regresi ini digunakan untuk mengukur kekuatan hubungan linier antara variabel bebas dengan variabel tergantung yang kemudian kita interpretasi sebagai besarnya pengaruh variabel bebas terhadap variabel tergantung. Koefesien regresi ini memuat 2 koefesien regresi, yaitu: koefesien regresi baku dengan notasi β dan koefesien regresi tidak baku dengan notasi b. Dalam regresi linier sederhana, kita akan menggunakan nilai koefesien regresi tidak baku (b) yang mempunyai rumusnya sebagai berikut. B= n XY− X Y n X2 − X 2 Koefisien regresi baku (Standaridzed regression coefficient (β)): nilai statistik dalam regresi linier yang menggambarkan kekuatan dan arah hubungan linier (linear association) antara variabel tergantung (kriteria) dan variabel bebas (prediktor). Nilai ini disebut baku karena kisaran nilainya antara -1 sampai dengan 1 (Cramer & Howitt, 2006). Jika nilainya semakin mendekati 1 maka hal tersebut menunjukkan hubungan antara kedua variabel semakin kuat dengan mengabaikan apakah positif atau negatif. Dengan demikian variabel bebas akan semakin kuat untuk digunakan memprediksi variabel tergantung. Karena prediktor – prediktor sudah distandarisasi maka hal tersebut memungkinkan untuk membandingkan kekuatan relatif hubungan atau bobot mereka dengan variabel tergantungnya. Jika tidak terdapat tanda (positif atau negatif), maka diinterpretasikan hubungan kedua variabel positif. Hubungan positif bermakna jika nilai pada prediktor tinggi, maka nilai pada variabel tergantung juga tinggi. Sebaliknya jika terdapat tanda negatif, maka hubungan kedua variabel tersebut negatif. Hubungan negatif mempunyai makna jika jika nilai pada prediktor tinggi, maka nilai pada variabel tergantung rendah. Koefesien dengan nilai sebesar 0,50 mempunyai makna bahwa untuk setiap kenaikan simpangan baku pada nilai prediktor, maka simpangan baku pada variabel tergantungnya naik sebesar 0,5. Koefesien regresi baku dapat diubah menjadi koefesien regresi yang tidak baku dengan cara mengkalikan koefesien regresi baku dengan deviasi standar (SD) variabel tergantung dan membaginya dengan deviasi standar prediktornya. Jika dirumuskan akan menjadi: Koefesien regresi tidak baku = Koefesien regresi baku x SD variabel tergantung SD variabel bebas Koefesien regresi baku (β) tidak digunakan dalam regresi linier sederhana kecuali dalam kasus-kasus tertentu saat kita melakukan standarisasi nilai ke dalam nilai Z karena varaibel-variabel yang kita teliti mempunyai unit pengukuran yang berbeda satu dengan yang lain. Koefesien ini digunakan dalam prosedur Analisis Jalur (Path Analysis) dan Structural Equation Modeling berbasis Partial Least Square. Koefisien regresi tidak baku (Unstandaridzed regression coefficient (b)): koefesien yang belum distandarisasi yang mempunyai nilai acak dan tidak terbatas lawan dari koefisien yang distandarisasi dengan nilai ± 1. Prediktor tertentu yang diukur dalam unit dengan nilai – nilai yang lebih besar akan terdapat kemungkinan mempunyai koefesien regresi parsial yang tidak baku yang lebih besar daripada prediktor tertentu yang diukur dalam unit nilai yang lebih kecil. Oleh karena itu, kita akan kesulitan membandingkan bobot relatif prediktor – prediktor tersebut saat mereka tidak diukur dengan menggunakan skala atau ukuran yang sama. Koefesien regresi tidak baku dapat diubah menjadi koefesien baku dengan cara mengkalikan koefesien regresi tidak baku dengan deviasi standar variabel bebas dengan dibagi oleh deviasi standar variabel tergantungnya. Koefesien regresi baku = Koefesien regresi tidak baku x SD variabel bebas SD variabel tergantung Dalam regresi linier sederhana, koefesien regresi yang kita pergunakan ialah koefesien regresi tidak baku (b). Nilai t dalam Regresi Linier Sederhana Nilai t diperoleh pada bagian keluaran koefesien regresi yang berfungsi untuk digunakan sebagai pengujian hipotesis secara parsial atau sendirisendiri saat kita menggunakan prosedur regresi linier sederhana dan berganda dimana kita menggunakan variabel bebas atau prediktor lebih dari 1. Pada saat kita merumuskan hipotesis dan melakukan pengujian hipotesis dengan nilai t maka bunyi hipotesis nol adalah nilai β adalah sama dengan 0. Dengan demikian jika koefesien regresi signifikan yang berarti nilainya tidak sama dengan 0, maka variabel bebas tersebut memberikan kontribusi secara signifkan terhadap perubahan nilai pada variabel tergantung. Kriteria pengujian hipotesis ini dilakukan dengan cara membandingkan antara nilai t hitung (to) dengan t tabel (t nilai kritis) dengan menggunakan ketentuan, yaitu: jika nilai t hitung > t tabel dengan tingkat signifikansi (α) tertentu, misalnya sebesar 0,05 maka H0 ditolak dan H1 diterima; sebaliknya jika nilai t hitung < t tabel maka H0 diterima dan H1 ditolak. Untuk memperoleh nilai t digunakan formula seperti di bawah ini to = 𝐛𝐤 𝐒𝐛𝐤 dengan Sb= Se= b Y2 −a Se X2 Y−b n−2 n XY X Y n X X 2 2 XY Nilai Probabilitas (p value) Bagian ANOVA (F) pada Keluaran SPSS Nilai ini dikeluarkan oleh SPSS yang dapat digunakan sebagai alternatif pengujian hipotesis simultan dengan Uji F dengan ketentuan sebagai berikut: jika nilai probabilitas hasil penghitungan < nilai alpha (α), misalnya 0,05; maka H0 ditolak dan H1 diterima; sebaliknya jika nilai probabilitas hasil penghitungan > nilai alpha (α), misalnya 0,05; maka H0 diterima dan H1 ditolak. Nilai Probabilitas (p value) Bagian Koefesien Regresi pada Keluaran SPSS Nilai ini dikeluarkan oleh SPSS yang dapat digunakan sebagai alternatif pengujian hipotesis parsial dengan Uji t dengan ketentuan sebagai berikut: jika nilai probabilitas hasil penghitungan < nilai alpha (α), misalnya 0,05; maka H0 ditolak dan H1 diterima; sebaliknya jika nilai probabilitas hasil penghitungan > nilai alpha (α), misalnya 0,05; maka H0 diterima dan H1 ditolak Persyaratan Pokok Penggunaan Regresi Linier yang Harus Dipenuhi Persyratan menggunakan regresi linier dalam SPSS didasarkan pada hal-hal sebagai berikut: Model regresi dikatakan layak jika angka signifikansi pada ANOVA sebesar < 0.05 Predictor yang digunakan sebagai variabel bebas harus layak. Kelayakan ini diketahui jika angka Standard Error of Estimate < Standard Deviation Koefesien regresi harus signifikan. Pengujian dilakukan dengan uji t. Koefesien regresi signifikan jika t hitung > t table (nilai kritis). Dalam IBM SPSS dapat diganti dengan menggunakan nilai signifikansi (sig) dengan ketentuan sebagai berikut: ◦ Jika sig < 0,05; koefesien regresi signifikan ◦ Jika sig > 0,05; koefesien regresi tidak signifikan Tidak boleh terjadi multikolinieritas, artinya tidak boleh terjadi korelasi antar variabel bebas yang sangat tinggi atau terlalu rendah. Syarat ini hanya berlaku untuk regresi linier berganda dengan variabel bebas lebih dari satu. Terjadi multikolinieritas jika koefesien korelasi antara variable bebas > 0,7 atau < - 0,7 Tidak terjadi otokorelasi jika: - 2 ≤ DW ≤ 2 Keselerasan model regresi dapat diterangkan dengan menggunakan nilai r2 semakin besar nilai tersebut maka model semakin baik. Jika nilai mendekati 1 maka model regresi semakin baik. Nilai r2 mempunyai karakteristik diantaranya: 1) selalu positif, 2) Nilai r2 maksimal sebesar 1. Jika Nilai r2 sebesar 1 akan mempunyai arti kesesuaian yang sempurna. Maksudnya seluruh variasi dalam variabel tergantung (variabel Y) dapat diterangkan oleh model regresi. Sebaliknya jika r2 sama dengan 0, maka tidak ada hubungan linier antara variabel bebas (variabel X) dan variabel tergantung (variabel Y). Terdapat hubungan linier antara variabel bebas (X) dan variabel tergantung (Y) Data harus berdistribusi normal Data berskala interval atau rasio Terdapat hubungan dependensi, artinya satu variabel merupakan variabel tergantung yang tergantung pada variabel (variabel) lainnya. Asumsi yang Melandasi Regresi Linier Variabel – (variabel) bebas atau predictor tidak boleh berkorelasi dengan error atau disturbance term jika ini terjadi maka metode Least Square (LS) yang digunakan untuk menaksir parameter yang tidak diketahui, yaitu koefesien regresi akan bias dan tidak konsisten Variabel bebas dan tergantung harus kuantitatif dan berskala metrik, dapat berskala interval ataupun rasio Tidak ada multikolinieritas. Artinya tidak ada hubungan linier sempurna antar predictor atau variabel bebas. Hubungan linier sempurna dicerminkan terjadinya korelasi yang sangat tinggi antar variabel bebas yang menurut Hair (2010) sebesar ≥ 0,9. Nilai-nilai statistik lain yang digunakan untuk menguji multikolinieritas diantaranya: nilai variance inflation factor (VIF) dengan ketentuan jika nilai VIF > 5, maka terjadi multikolinieritas; nilai condition index dengan ketentuan jika nilai condition index > 5, maka terjadi multikolinieritas. Asumsi ini hanya berlaku pada regresi linier berganda saat variabel bebas lebih dari satu. Variabel bebas yang digunakan sebagai predictor tidak boleh berkorelasi dengan variabel eksternal yang tidak dimasukkan dalam model regresi yang kita buat Tidak boleh terjadi heteroskedastisitas. untuk memahami pengertian heteroskedastisitas diperlukan memahami terlebih dahulu pengertian homoskedastisitas. Homoskedastisitas adalah deskripsi data dimana varian batas kesalahan (error terms / e) kelihatan konstan diluar jangkauan dari nilai – nilai variabel bebas tertentu. Asumsi kesamaan varian kesalahan populasi ε (dimana ε diestimasi dari nilai sampel e) kritis jika diaplikasikan pada regresi linier yang benar. Saat batas kesalahan mempunyai varian yang semakin besar, maka data disebut bersifat heteroskedastisitas. Dengan kata lain, homoskedastisitas merupakan asumsi dimana variable tergantung menunjukkan tingkatan varian yang sama untuk semua variable bebasnya. Jika penyebaran nilai varian pada semua variable bebas tidak sama maka hubungan tersebut dikatakan sebagai heteroskedastisitas. Untuk menguji homoskedastisitas (terjadinya kesamaan varian pada semua variable bebas) digunakan pengujian Levene pada data variable berskala non-metrik. Terjadi kesamaan varian jika nilai signifikansi (sig) pada Levene test > 0,05. Pengujian Levene dapat dijelaskan dengan membuat hipotesis awal (H0) yang berbunyi “ varian pada semua variable bebas sama” dan hipotesis alternatif (H1) yang berbunyi “varian pada semua variable bebas tidak sama”. Ketentuan pengujian hipotesis didasarkan pada nilai signifikansi: jika nilai sig > 0,05 H0 diterima; jika nilai sig < 0,05 H0 ditolak. Jika variable-variabel berskala metrik kita dapat menggunakan pengujian Box’s M. Ketentuan pengujiannya sama dengan cara pengujian menggunakan Levene test. Untuk mengetahui apakah terjadi herteroskedastisitas dalam pengujian diatas dapat diketahui dari nilai signfikansinya. Jika nilai signfikansi (sig) < 0,05, maka dalam model tersebut terjadi heteroskedastisitas. Jika menggunakan grafik, maka terjadi heteroskedastisitas dalam model regresi jika titik – titik dalam scaterplot membentuk pola –pola tertentu atau berkumpul disatu sisi atau dekat nilai 0 pada sumbu Y pada kurva yang dihasilkan saat kita menggambar kurva dengan menggunakan SPSS. Jika titik – titik data menyebar tidak secara beraturan, maka tidak terjadi heteroskedastisitas. Tidak terjadi otokorelasi. Terjadi korelasi dalam variabel bebas yang mengganggu hubungan variabel bebas tersebut dengan variabel tergantung. Otokorelasi terjadi saat dua observasi atau nilai berkorelasi dalam satu variabel. Untuk pengujian otokorelasi kita menggunakan nilai dari Durbin – Watson (DW). Kisaran nilai DW mulai dari 0 – 4. Tidak terjadi otokorelasi jika: - 2 ≤ DW ≤ 2 (Anderson, 2001:733) Kesalahan yang terdistribusi secara normal. Diasumsikan bahwa residual dalam model bersifat random, variabel – variabel terdistribusi secara normal dengan rata-rata sebesar 0. Linieritas. Mempunyai arti bahwa nilai rata-rata variabel tergantung untuk masing-masing kenaikan variabel bebas terletak pada garis lurus. Dengan kata lain model regresi yang kita buat bersifat linier. Menggunakan Regresi Linier dalam SPSS Untuk menggunakan prosedur tersebut dalam SPSS kita memerlukan tahapan sebagai berikut: Pertama: Aktifkan SPSS versi 23 Setelah SPSS aktif, masuk kedalam Data Editor dan pilih sub-menu di bagian kiri bawah Variabel View. Setelah itu buatlah desain variabel untuk kedua variabel yang kita pergunakan dalam penelitian dengan mengisikan informasi sesuai dengan Default Variable View pada kolom – kolom yang tersedia seperti pada contoh di bawah ini Name Type Width Decimal Label Values Missing Column Align Measure Role Bulan String 8 0 Bulan None None 8 R Nominal Input Jtk Numeric 8 2 Jumlah Tenaga Kerja None None 8 R Scale Input Biaya_ptl Numeric 8 2 Biaya produksi tidak langsung None None 8 R Scale Target Setelah selesai memasukan informasi yang diminta maka klik perintah Data View yang berada disamping perintah Variable View Kedua: Masukkan data pada posisi Data View Masuk ke perintah Data View, dimana tampilan dibaca sebagai berikut: Kolom dibaca sebagai Variabel. Kita akan melihat tampilan pada kolom Case Label Bulan, Variabel Jumlah Tenaga Kerja dan Variabel Biaya Produksi Tidak Langsung Pada Baris masih kosong. Isikan data ke 1 pada baris pertama sampai dengan data ke 12 pada baris kedua belas dari kiri atas ke bawah sebagaimana tampilan di bawah ini: 1 . . 12 bulan Januari jtk 20 biaya_ptl 200 Desembe r 14 60 Ketiga: Melakukan analisis Setelah selesai memasukkan semua data tersebut, kita akan melakukan tahap analisis data seperti di bawah ini Klik Analyse > Regression: pilih Linear Pindahkan variabel tergantung biaya tidak langsung ke kolom Dependent Pindahkan variabel bebas jumlah tenaga kerja ke kolom Independent Masukkan variabel bulan ke kolom Case Labels Isi kolom Method dengan perintah Enter (*memasukkan semua variabel ke dalam proses kalkulasi) Klik Option: Pada pilihan Stepping Method Criteria masukkan angka 0,05 pada kolom Entry (mempunyai pengertian bahwa Tingkat Keyakinan yang kita pergunakan sebesar 95%) Cek Include constant in equation Pada pilihan Missing Values cek Exclude cases listwise > Tekan Continue Pilih Statistics: Pada pilihan Regression Coefficient pilih Estimate (untuk menghitung nilai koefesien regresi b), Model Fit (untuk menghitung nilai F, R, R2, dan Adjusted R2) dan Descriptive (untuk menghitung nilai rata-rata, deviasi standar dan korelasi). Pada pilihan Residual (untuk mengeluarkan selisih nilai observasi dengan nilai prediksi), pilih Case wise Diagnostics dan cek All Cases (untuk menghasilkan nilai prediksi sesuai dengan jumlah data) > Tekan Continue Klik Plots untuk membuat Grafik Isi kolom Y dengan pilihan SDRESID (studentized residual) dan kolom X dengan ZPRED (nilai prediksi baku variabel tergantung didasarkan pada model), kemudian tekan Next Isi lagi kolom Y dengan ZPRED dan kolom X dengan DEPENDNT (variabel keluaran / hasil) Pada pilihan Standardised Residual Plots (untuk mengeluarkan Kurva Residual Baku), cek Normal Probability Plot (untuk mengeluarkan Kurva Probabilitas Normal) > Tekan Continue Klik OK untuk diproses *Catatan: Dalam SPSS disediakan dua metode utama, yaitu metode Enter dan metode Stepwise yang terdiri dari Stepwise, Forward dan Backward) yang digunakan untuk Regresi Linier Berganda. Metode Enter mempunyai pengertian semua variabel dikalkulasi berdasarkan kriteria (default) nya SPSS. Dalam regresi linier sederhana kita menggunakan metode Enter. Metode Stepwise mempunyai pengertian kalkulasi hubungan antara variabel – variabel bebas dengan variabel tergantung didasarkan pada sejauh mana variabel-variabel tersebut berkorelasi tinggi dengan variabel tergantung. Metode Forward dalam SPSS sama dengan Stepwise letak perbedaannya dalam metode Forward akan ada pembuangan (removal) variabel bebas yang kurang berdampak signifikan pada variabel tergantung; sedang metode Backward memprioritaskan penghitungan dengan didasarkan pada urutan signifikansi variabel – variabel bebas yang digunakan sebagai predictor. Variabel bebas yang memberi kontribusi paling signifikan akan didahulukan kemudian diikuti dengan variabel yang signfikan dan akhirnya kurang signfikan. Pemilihan metode ini hanya berlaku saat kita menggunakan variabel bebas lebih dari satu dalam regresi linier berganda. Hasil analisis akan tertera di bagian berikut ini. Kita akan melaknjutkan langkah ke 4, yaitu membuat interpretasi hasil analisis dengan menggunakan prosedur regresi linier. Keempat: Membuat interpretasi hasil analisis Bagian I: Statistik Deskriptif Descriptive Statistics Mean Biaya Produksi Tidak Langsung Jumlah Tenaga Kerja Std. Deviation N 147.8333 71.97832 12 23.4167 7.15362 12 Bagian ini untuk digunakan untuk menafsir besarnya rata-rata biaya produksi tidak langsung dan jumlah tenaga kerja. Rata-rata biaya produksi tidak langsung ialah sebesar 147,8333 dan ratarata jumlah tenaga kerja sebesar 23,4167 selama dua belas bulan. Standard Deviasi variabel biaya produksi tidak langsung ialah sebesar 71,978323 sedang untuk variabel jumlah tenaga kerja sebesar 7,15362. Nilai standar deviasi merupakan nilai simpangan baku yang menunjukkan dispersi data; dengan demikian nilai dapat diinterpretasi jika nilai semakin kecil (mendekati 0) maka nilai ini menunjukkan data yang bersifat homogen. Jika satuan nilai data observasi dalam jumlah besar, misalnya jutaan maka setidak-tidaknya nilai standar deviasi lebih kecil dari nilai ratarata. Jumlah kasus (N) sebanyak 12 Bagian II: Korelasi Antara Variabel Jumlah Tenaga Kerja dengan Biaya Produksi Tidak Langsung Dalam menggunakan regresi linier pembaca harus memahami bahwa SPSS akan mengeluarkan nilai Korelasi antara dua variabel yang kita teliti. Meski angka ini tidak akan kita pergunakan untuk menjawab rumusan masalah di atas; kita akan membahas nilai korelasi dan intepretasinya. Nilai korelasi dalam Regresi Linier Sederhana merupakan nilai koefesien korelasi Pearson yang diperoleh dengan cara menghitung nilai koefesien korelasi dengan menggunakan rumus Korelasi Pearson sebagai berikut: r= n n X2 − XY− X X 2 − n Y Y2− Y 2 Selain itu kita juga dapat menghitungnya dengan cara mengakarkan nilai R2 ; oleh karena itu nilai koefesien korelasi (R atau r ) berguna juga untuk melihat kelayakan model regresi linier sederhana yang kita buat. Ketentuannya jika nilai R semakin tinggi maka model regresi semakin layak. Hal ini mudah dipahami karena jika nilai R tinggi, maka hubungan kedua variabel semakin linier (membentuk garis lurus). Adapun kegunaan utama koefesien korelasi Pearson ialah: Pertama: mengukur kekuatan hubungan dua variabel Kedua: melihat signifikansi hubungan dua variabel Ketiga: melihat arah hubungan dua variabel. Terdapat 2 tipe arah hubungan dalam korelasi, yaitu hubungan searah atau positif dan hubungan tidak searah atau negatif. Correlations Pearson Correlation Sig. (1-tailed) N Biaya Produksi Tidak Langsung Jumlah Tenaga Kerja Biaya Produksi Tidak Langsung Jumlah Tenaga Kerja Biaya Produksi Tidak Langsung Jumlah Tenaga Kerja Biaya Produksi Tidak Langsung Jumlah Tenaga Kerja 1.000 .690 .690 1.000 . .007 .007 . 12 12 12 12 Keluaran di atas mempunyai makna sebagai berikut. Besar korelasi atau hubungan antara variabel jumlah tenaga kerja dan biaya produksi tidak langsung ialah 0,690. Artinya hubungan kedua variabel tersebut kuat karena nilainya lebih besar dari 0,5. Kisaran korelasi antara 0 – 1 dan koefesien korelasi dapat positif (+) atau negatif (-); sehingga kisaran tersebut dapat dirumuskan menjadi antara -1 s/d 1. Jika koefesien korelasi diketemukan positif maka hubungan kedua variabel yang disebut mempunyai korelasi postif; sebaliknya jika koefesien korelasi diketemukan negatif maka hubungan kedua variabel yang disebut mempunyai korelasi negatif. Ketentuannya kuat lemahnya hubungan antara dua variabel yang dikorelasikan ialah semakin mendekati 1, maka korelasi antara kedua variabel semakin kuat; sebaliknya semakin mendekati 0, maka korelasi antara kedua variabel semakin lemah. Sebagai pedoman berikut disampaikan ketentuan selengkapnya ◦ 0 : Tidak ada korelasi antara dua variabel ◦ >0 – 0,25: Korelasi sangat lemah ◦ >0,25 – 0,5: Korelasi cukup ◦ >0,5 – 0,75: Korelasi kuat ◦ >0,75 – 0,99: Korelasi sangat kuat ◦ 1: Korelasi sempurna Hubungan antara variabel jumlah tenaga kerja dan biaya produksi tidak langsung signifikan jika dilihat dari angka signifikansi (sig) sebesar 0,007 yang lebih kecil dari 0,05. Jika angka signifikansi < dari 0.05 artinya ada hubungan yang signifikan antara kedua variabel tersebut. Sebagai tambahan jika pada tabel keluaran koefesien korelasi ditandai dengan dua bintang (**); maka signifikansi (sig) pembanding bukan 0,05 tetapi 0,01. Nilai koefesien korelasi yang dihasilkan positif (0,690) mempunyai makna bahwa hubungan antara variabel jumlah tenaga kerja dan biaya produksi tidak langsung searah. Artinya jika jumlah tenaga kerja besar, maka biaya produksi tidak langsung akan meningkat Bagian III Variabel yang Dimasukkan Variables Entered/Removedb Model 1 Variables Entered Jumlah Tenaga a Kerja Variables Removed Method . Enter a. All requested variables entered. b. Dependent Variable: Biaya Produksi Tidak Langsung Bagian ini menunjukkan metode dalam memasukkan variabel Pada bagian ini kita memasukkan semua variabel yang akan dianalisis dan tidak ada variabel yang kita keluarkan karena kita menggunakan metode “Enter” Metode yang lain yang disediakan dalam perintah Method ialah a) stepwise, b) forward, dan backward. Bagian IV Ringkasan Model (Koefesien Determinasi) Model Summaryb Model 1 R R Square a .690 .476 Adjusted R Square .423 Std. Error of the Estimate 54.65795 a. Predictors: (Constant), Jumlah Tenaga Kerja b. Dependent Variable: Biaya Produksi Tidak Langsung Keluaran di atas menunjukkan besarnya nilai R2 yang diperoleh dengan menggunakan rumus sebagai berikut: 𝑆𝑆𝑟𝑒𝑔 2 R= 𝑆𝑆𝑡𝑜𝑡𝑎𝑙 =1- 𝑆𝑆𝑟𝑒𝑠 𝑆𝑆𝑡𝑜𝑡𝑎𝑙 Untuk memudahkan interpretasinya kita menjadikan nilai tersebut kedalam bentuk persen yang kemudian kita sebut sebagai Koefesien Determinasi yang berfungsi untuk mengetahui besarnya proporsi variasi variabel tergantung biaya produksi tidak langsung yang dapat dijelaskan dengan menggunakan variabel bebas jumlah tenaga kerja atau dengan kata lain yang dapat dijelaskan dalam model yang kita buat. Dengan menggunakan bahasa umum nilai Koefesien Determinasi digunakan untuk menghitung besarnya pengaruh variabel bebas terhadap variabel tergantung. Koefesien determinasi dihitung dengan cara mengkalikan nilai R2 dengan 100% (R2 x 100%) Angka R Square sebesar 0,476. Jika dijadikan sebagai Koefesien Diterminasi akan tersebut menjadi 0,476 dikalikan dengan 100% sama dengan 47,6%. Angka tersebut mempunyai pengertian bahwa sebesar 47,6% biaya produksi tidak langsung yang terjadi dapat dijelaskan dengan menggunakan variabel bebas jumlah tenaga kerja. Dengan bahasa umum kita dapat katakan bahwa variabel bebas jumlah tenaga kerja mempengaruhi variabel tergantung biaya produksi tidak langsung. Sedang sisanya, yaitu 52,4% atau (100% - 47,6%) harus dijelaskan oleh faktor-faktor penyebab lainnya diluar model regresi ini. Untuk diketahui bahwa besarnya R square berkisar antara 0 –1 yang berarti semakin kecil besarnya R square, maka variasi pada variabel tergantung kurang dapat dijelaskan dengan menggunakan variabel bebas yang kita pilih. Sebaliknya jika R square semakin mendekati 1, maka variasi variabel tergantung semakin dapat dijelaskan dengan menggunakan variabel bebas yang ada dalam model riset kita. Besarnya Standar Error of the Estimate (SEE) ialah 54,65795 (untuk variabel biaya produksi tidak langsung). Jika angka tersebut dibandingkan dengan angka Standar Deviasi (STD), sebesar 71,97832, maka angka SEE ini lebih kecil. Dengan demikian variabel bebas jumlah tenaga kerja yang digunakan sebagai predictor dalam menentukan besarnya biaya produksi tidak langsung sudah benar. Ketentuannya ialah predictor untuk variabel tergantung sudah benar jika nlai SEE lebih kecil dari angka standard deviasi (SEE < STD). Bagian V Anova: Pengujian Kelayakan Model Regresi Keluaran ini digunakan untuk melakukan pengujian kelayakan model atau pengujian secara simultan jika digunakan dalam regresi linier berganda. ANOVAb Sum of Model Squares 1 Regression 27114.754 Residual 29874.913 Total 56989.667 df Mean Square 1 27114.754 10 2987.491 11 a. Predictors: (Constant), Jumlah Tenaga Kerja b. Dependent Variable: Biaya Produksi Tidak Langsung F 9.076 Sig. .013a Bagian ini menunjukkan besarnya nilai F dan angka probabilitas atau signifikansi (Sig) pada perhitungan Anova yang akan digunakan untuk uji kelayakan model regresi dengan ketentuan: Jika menggunakan nilai F; maka nilai F hitung (Fo) harus lebih besar dari F tabel (Fα) Jika menggunakan nilai probabilitas, maka model yang baik harus mempunyai nilai signifkansi < 0,05. Pada keluaran di atas menghasilkan: Bagian keluaran ANOVA menghasilkan angka F sebesar 9,076 dengan tingkat signifikansi (angka probabilitas) sebesar 0,013. Karena angka probabilitas 0,013 < dari 0,05, maka model regresi ini sudah layak untuk digunakan dalam memprediksi biaya produksi tidak langsung.Untuk dapat digunakan sebagai model regresi yang dapat digunakan dalam memprediksi variabel tergantung, maka angka signifikansi (sig) harus < (lebih kecil) dari 0,05 Untuk melakukan pengujian kelayakan model regresi yang kita buat dengan data yang kita miliki, langkah – langkahnya sebagai berikut: Menggunakan nilai F Seperti tertera pada keluaran di atas SPSS juga mengeluarkan nilai signfikansi (sig) selain nilai F yang dapat kita pergunakan sebagai alternatif lain untuk melakukan pengujian hipotesis dengan nilai F. Pertama: Membuat hipotesis H0: β=0 (Variabel jumlah tenaga kerja tidak berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung) H1: β≠ 0 (Variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung). Kedua: Menghitung nilai F hitung (Fo) dengan rumus sebagai berikut F= 𝑺𝑺𝒓𝒆𝒈/(𝒌−𝟏) 𝑺𝑺𝒓𝒆𝒔/(𝒏−𝒌) Dari penghitungan SPSS diperoleh nilai Fo sebesar 9,076. Ketiga: Menggunakan kriteria sebagai berikut: Jika nilai F hitung (Fo) > F tabel (Fα); maka H0 ditolak dan H1 diterima Jika nilai F hitung (Fo) < F tabel (Fα); maka H0 diterima dan H1 ditolak Keempat: Menghitung nilai F tabel yang diperoleh dari Tabel Nilai F dengan ketentuan sebagai berikut: Nilai α sebesar 0,05 dan Degree of Freedom (DF) untuk numerator = jumlah variabel – 1 atau (k-1) dan denominator = jumlah data – jumlah variabel atau (n – k). Dengan demikian nilai F tabel untuk numerator adalah: 2 – 1 = 1 dan denominator adalah: 12 – 2 = 10; maka diperoleh nilai F dari tabel sebesar 4,96. Kelima: Mengambil keputusan Diperoleh dari hasil penghitungan nilai F hitung sebesar 9,076 > nilai F tabel sebesar 4,96; maka H0 ditolak dan H1 diterima. Artinya variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung. Pengujian dengan nilai F juga dapat dilakukan dengan cara menggunakan kurva sebagai berikut: Gambar kurva menunjukkan bahwa nilai Fo jatuh atau berada di daerah H0 ditolak oleh karena itu H1 diterima. Artinya variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung. Menggunakan nilai signifikansi Pertama: Menentukan hipotesis H0: Variabel jumlah tenaga kerja tidak berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung H1: Variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung Kedua: Menggunakan kriteria pengambilan keputusan Kirteria pengambilan keputusan pengujian hipotesis sebagai berikut Jika nilai signifkansi atau probabilitas hitung < 0,05; maka H0 ditolak dan H1 diterima Jika nilai signifkansi atau probabilitas hitung > 0,05; maka H0 diterima dan H1 ditolak Ketiga: Mengambil keputusan Dari tabel keluaran di atas diketahui nilai signifikansi pada kolom Sig sebesar 0,013 < 0,05; maka H0 ditolak dan H1 diterima. Artinya variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung. Baik menggunakan nilai F maupun nilai signifikansi menunjukkan bahwa variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung. Dengan demikian model regresi yang kita buat sudah benar. Bagian VI Koefisen Regresi Keluaran ini digunakan untuk melakukan pengujian hipotesis signifkansi koefisien regresi. Koefesien regresi mewakili slope atau gradient dalam garis regresi. Nilai ini mewakili perubahan pada variabel tergantung akibat dari perubahan unit dalam variabel bebas atau predictor-nya. Dengan kata lain besarnya perubahan dalam satu unit pada predictor akan mengubah (dapat secara positif atau negatif) nilai pada variabel tergantungnya. Koefesien regresi yang akan dipergunakan dalam regresi linier sederhana ialah koefesien regresi tidak baku (unstandardized coeficients) atau b1 (untuk diketahui dalam regresi linier sederhana kita dapat menggunakan notasi b saja karena jumlah variabel bebas hanya 1) yang dalam SPSS diberi simbol B terletak pada kolom unstandardized coeficients. Koefesien regresi lainnya ialah nilai konstan (Constant) yang mempunyai notasi a atau b0 yang dalam SPSS diberi notasi B. Nilai ini mempunyai makna besarnya nilai variabel tergantung (Y) saat variabel bebas bernilai 0 (saat X = 0). Nilai ini dapat postif dan negatif. Coefficientsa Model 1 (Constant) Jumlah Tenaga Kerja Unstandardized Coefficients B Std. Error -14.686 56.206 6.940 2.304 Standardized Coefficients Beta a. Dependent Variable: Biaya Produksi Tidak Langsung .690 t -.261 3.013 Sig. .799 .013 Bagian ini menggambarkan persamaan regresi untuk mengetahui angka konstan (Constant), dan uji hipotesis signifikansi koefesien regresi: Persamaan regresinya adalah: Y=a+bx Dimana: Y = biaya produksi tidak langsung X = data jumlah tenaga kerja hasil observasi a = angka konstan dari Unstandardized Coefficient yang dalam penelitian ini ialah sebesar 14,686. Angka ini berupa angka konstan yang mempunyai arti: jika tidak ada tambahan satu tenaga kerja (pada saat X = 0), maka biaya produksi tidak langsung akan berkurang sebesar 14,686 b = angka koefisien regresi sebesar + 6,940. Angka tersebut mempunyai arti bahwa setiap penambahan 1 tenaga kerja, maka biaya produksi tidak langsung akan meningkat sebesar 6,940. Sebaliknya jika angka ini negatif ( - ) maka biaya produksi tidak langsung akan menurun sebesar angka tersebut. Oleh karena itu, persamaannya menjadi: Y = -14,686 + 6,940 X Untuk melakukan pengujian hipotesis dapat kita lakukan dengan menggunakan nilai t hitung (to) atau nilai signifikansi (sig atau α) dengan langkah-langkahnya sebagai berikut: Pengujian dengan menggunakan nilai t Pertama: Menentukan hipotesis H0: b=0 (Variabel jumlah tenaga kerja tidak berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung) H1: b≠0 (Variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung) Kedua: Menghitung nilai t hitung Dari penghitungan dengan menggunakan SPSS diperoleh nilai sebesar 3,013 Ketiga: Menggunakan kriteria sebagai berikut: Jika nilai t hitung (to) > t tabel (tα); maka H0 ditolak dan H1 diterima Jika nilai t hitung (to) < t tabel (tα); maka H0 diterima dan H1 ditolak Keempat: Menghitung nilai t tabel yang diperoleh dari Tabel Nilai t dengan ketentuan sebagai berikut: Nilai α sebesar 0,05 dan Degree of Freedom (DF)= n -2. Karena pengujian dilakukan dengan dua sisi (yaitu b = 0 atau b ≠0); maka nilai α harus dibagi 2 dengan demikian nilainya menjadi α/2 = 0,05/2 hasilnya ialah 0,025. Ketentuan nilai t hitung menjadi α sebesar 0,025 dengan DF 12 – 2 = 10. Dari tabel t diketemukan sebesar 2,28. Kelima: Mengambil keputusan Diperoleh dari hasil penghitungan nilai t hitung sebesar 3,013 > nilai t tabel sebesar 2,28; maka H0 ditolak dan H1 diterima. Artinya variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung. Pengujian dengan nilai t juga dapat dilakukan dengan cara menggunakan kurva sebagai berikut: Jika nilai t hitung (to) positif, maka pengujian dilakukan disebelah kanan; sebaliknya jika nilai t hitung (to) negatif, maka pengujian dilakukan disebelah kiri. Pada kurva di atas kita melakukan pengujian hipotesis di sebelah kanan karena hasil nilai t hitung positif. Kita lihat bahwa nilai t hitung berada di daerah H0 ditolak, maka H1 diterima. Artinya variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung. Pengujian dengan nilai signifikansi (sig) Seperti tertera pada keluaran di atas SPSS juga mengeluarkan nilai signfikansi (sig) selain nilai t yang dapat kita pergunakan sebagai alternatif lain untuk melakukan pengujian hipotesis dengan nilai t. Pertama: Menentukan hipotesis H0: Variabel jumlah tenaga kerja tidak berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung H1: Variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung Kedua: Menggunakan kriteria pengambilan keputusan Kirteria pengambilan keputusan pengujian hipotesis sebagai berikut Jika nilai signifkansi atau probabilitas hitung < 0,05; maka H0 ditolak dan H1 diterima Jika nilai signifkansi atau probabilitas hitung > 0,05; maka H0 diterima dan H1 ditolak Ketiga: Mengambil keputusan Dari tabel keluaran di atas diketahui nilai signifikansi pada kolom Sig sebesar 0,013 < 0,05; maka H0 ditolak dan H1 diterima. Artinya variabel jumlah tenaga kerja berpengaruh secara signifikan terhadap variabel biaya produksi tidak langsung. Baik menggunakan nilai t ataupun nilai signifikansi akan menghasilkan keputusan yang sama. Catatan: Dalam regresi linier sederhana pengujian hipotesis kelayakan model dan signifikansi koefesien regresi sama. Hal ini akan berbeda pada regresi linier berganda dimana pada pengujian kelayakan model dengan menggunakan nilai F atau Signifikansi pada keluaran ANOVA disebut sebagai pengujian simultan; sedang pengujian signifikansi koefesien regresi pada keluaran Coefficients dengan menggunakan nilai t atau signfikansi disebut sebagai pengujian parsial. Bagian VII Diagnosa per Kasus Keluaran berikut ini merupakan keluaran nilai prediksi dan residual atau selisih antara nilai observasi dengan nilai yang diprediksi. Nilai prediksi merupakan nilai yang diperoleh dengan menggunakan persamaan regresi linier Y= a + b x. Nilai residual diperoleh dengan cara nilai observasi dikurangi dengan nilai prediksi. Casewise Diagnosticsa Case Number 1 2 3 4 5 6 7 8 9 10 11 12 Bulan Januari Februari Maret April Mei Juni Juli Agustus Septem b e Oktober Novem be r Desem be r Std. Residual .118 -.344 .742 .423 .723 -.964 -.740 -1.513 Biaya Produksi Tidak Langsung 200.00 140.00 130.00 175.00 240.00 120.00 160.00 90.00 Predicted Value 193.5239 158.8222 89.4188 151.8819 200.4642 172.7029 200.4642 172.7029 Residual 6.47609 -18.82221 40.58120 23.11813 39.53575 -52.70289 -40.46425 -82.70289 2.075 300.00 186.5836 113.41643 .373 89.00 68.5978 20.40222 -.482 70.00 96.3591 -26.35914 -.411 60.00 82.4785 -22.47846 a. Dependent Vari able: Biaya Produksi Tidak Langsung Keluaran di atas ini menunjukkan hasil prediksi persamaan regresi. Pembahasan dimulai dari Case Number 1, untuk bulan Januari, maka persamaan regresinya adalah: Y= a + b x Y = -14,686 + 6,940 x 30 Untuk bulan Januari besarnya jumlah tenaga kerja (variabel X) berdasarkan data observasi ialah sebesar:30, maka persamaannya menjadi sebagai berikut: Y = -14,686 + (6,940 x 30). Hasilnya jika dihitung secara manual ialah sebesar 193, 514 Angka ini sama dengan angka biaya produksi tidak langsung yang diprediksi (predicted value) pada kasus bulan Januari sebesar 193,5239 yang dihitung oleh SPSS. Untuk penghitungan kasus lain pada -kasus bulan berikutnya kita dapat melihat pada keluaran di kolom Predicted value Kolom residual memberikan penjelasan adanya selisih antara biaya produksi tidak langsung sebenarnya dengan biaya produksi tidak langsung yang diprediksikan atau 200 – 193, 5239 = 6,47609. Jika selisih semakin kecil maka prediksi semakin akurat; sebaliknya jika selisih semakin besar maka prediksi semakin tidak akurat Kolom Std Residual (standardised residual) menyatakan residual yang distandarkan dengan cara: Residual dibagi dengan Standard Error of the Estimate (SEE). Untuk kasus pertama: 6,4709/54,65795 = 0,1188. Angka SEE 54,65795 berasal dari penafsiran bagian IV (model summary), angka ini berlaku untuk 12 kasus yang diteliti. Besar kecilnya angka residual dan std residual memberikan makna bagi persamaan regresi yang akan digunakan untuk memprediksi nilai variabel tergantung. Semakin kecil angka angka residual dan std residual, maka model regresi semakin baik untuk digunakan dalam memprediksi. Kecenderungan biaya produksi tidak langsung ialah mengalami kenaikan dan penurunan jika dilihat pada kolom Biaya Produksi Tidak Langsung dan Predicted Value serta Residual sebagai selisih antara nilai observasi variabel Biaya Produksi Tidak Langsung dengan nilai Biaya Produksi Tidak Langsung yang diprediksi.Selisih negatih (-) menunjukkan prediksi kenaikan sedang selisih positif (+) menunjukkan penurunan. Bagian VIII Statistik Residual Re siduals Sta tisticsa Minimum Predic ted V alue 68.5978 St d. P redic ted Value -1. 596 St andard E rror of 15.836 Predic ted V alue Adjust ed P redicted Value 59.2210 Residual -82.70289 St d. Residual -1. 513 St ud. Residual -1. 600 Deleted Residual -92.52368 St ud. Deleted Residual -1. 760 Mahal. Dis tanc e .007 Cook's Dis tanc e .002 Centered Leverage Value .001 Maximum 200.4642 1.060 Mean 147.8333 .000 St d. Deviat ion 49.64854 1.000 N 30.671 21.893 4.505 12 209.6794 113.41644 2.075 2.236 131.68236 2.999 2.547 .403 .232 146.9441 .00000 .000 .007 .88919 .057 .917 .082 .083 50.95604 52.11431 .953 1.030 60.86261 1.206 .752 .109 .068 12 12 12 12 12 12 12 12 12 12 12 a. Dependent Variable: Biaya Produksi Tidak Langs ung Bagian ini memberikan penjelasan mengenai nilai minimum biaya produksi tidak langsung yang diprediksi, yaitu sebesar: 68,5978; nilai maksimum biaya produksi tidak langsung yang diprediksi sebesar: 200,4642; rata-rata biaya produksi tidak langsung yang diprediksi sebesar 147,8333. Angka ini berlaku untuk semua kasus yang diteliti. Bagian IX Grafik 1: Persyaratan Normalitas (Normal Probability Plot) Normal P-P Plot of Regression Standardized Residual Dependent Variable: Biaya Produksi Tidak Langsung 1.0 Septembe Mei Maret Expected Cum Prob 0.8 April Oktober 0.6 Januari Februari 0.4 November Desember Juli Juni 0.2 Agustus 0.0 0.0 0.2 0.4 0.6 Observed Cum Prob 0.8 1.0 Grafik di atas menunjukkan pemenuhan persyaratan normalitas sebaran data, yaitu jika residual berasal dari distribusi normal, maka nilai-nilai sebaran data akan berada pada area di sekitar garis lurus sebagaimana sudah di bahas dibagian di atas bahwa penggunaan regresi linier sederhana adalah melakukan estimasi nilai variabel tergantung berdasarkan pada persamaan garis lurus. Dari hasil penghitungan kita lihat grafik di atas menunjukkan bahwa sebaran data berada pada posisi di sekitar garis lurus yang membentuk garis miring dari arah kiri bawah ke kanan atas; oleh karena itu persyaratan normalitas sudah dipenuhi. Bagian X Grafik 2: Persyaratan Kelayakan Model Regresi (Model Fit) Scatterplot Dependent Variable: Biaya Produksi Tidak Langsung Regression Studentized Deleted (Press) Residual Septembe 3 2 Maret 1 Mei Oktober April Januari 0 Februari Desember Juli November Juni -1 Agustus -2 -2 -1 0 1 Regression Standardized Predicted Value Grafik di atas memberikan penjelasan adanya hubungan antara nilai yang diprediksi (biaya produksi tidak langsung) dengan Studentised Delete Residual masing-masing. Keterangannya adalah sebagai berikut: Model regresi layak digunakan untuk memprediksi jika data yang tersebar berpencar disekitar angka 0 (nol) pada sumbu Y serta tidak membentuk pola atau kecenderungan tertentu. Jika kita lihat sebaran data di atas berada di area titik nol sumbu Y, maka model regresi ini layak digunakan untuk memprediksi penjualan. Dari gambar di atas hanya tiga data yang tidak terletak disekitar titik 0, yaitu kasus pada bulan Agustus dan September yang terletak secara ekstrim di sebelah kanan atas. Bagian XI Grafik 3: Persyaratan Model Fit Tiap Data Scatterplot Dependent Variable: Biaya Produksi Tidak Langsung Regression Studentized Deleted (Press) Residual Septembe 3 2 Maret 1 Mei Oktober April Januari 0 Februari Desember Juli November Juni -1 Agustus -2 -2 -1 0 1 Regression Standardized Predicted Value Grafik di atas menunjukkan adanya hubungan antara variabel biaya produksi tidak langsung dengan nilai prediksinya. Model yang memenuhi persyaratan ialah sebaran dimulai dari sebelah kiri bawah kemudian lurus kearah kanan dan keatas. Jika dilihat sebaran data di atas, maka dapat disimpulkan bahwa sebaran data sudah mengikuti persyaratan model keselarasan tiap data. Kesimpulannya model regresi ini layak untuk digunakan dalam memprediksi biaya produksi tidak langsung. Kasus Kedua Perusahaan ingin melakukan prediksi besarnya jumlah prediksi biaya yang akan dikeluarkan dengan menggunakan dua variabel bebas, yaitu biaya tetap dan biaya variabel. Dengan menggunakan data di bawah ini lakukan prediksi jumlah biaya yang akan dikeluarkan oleh perusahaan serta analisis besarnya pengaruh variabel bebas biaya tetap dan biaya variabel terhadap jumlah prediksi biaya yang akan dikeluarkan oleh pihak perusahaan: Bulan Januari Februari Maret April Mei Juni Juli Agustus Septembe Oktober November Desember Jumlah Biaya 210.00 215.00 220.00 225.00 230.00 235.00 240.00 245.00 250.00 255.00 260.00 270.00 Prediksi Biaya Tetap 30.00 35.00 40.00 43.00 48.00 50.00 55.00 58.00 62.00 65.00 68.00 70.00 Biaya Variabel 40.00 45.00 48.00 50.00 53.00 56.00 60.00 63.00 65.00 68.00 70.00 75.00 Adapun rumusan masalahnya sebagai berikut: Berapa besar pengaruh variabel biaya tetap dan biaya variabel terhadap variabel jumlah prediksi biaya secara bersama? Berapa besar pengaruh variabel biaya tetap dan biaya variabel terhadap variabel jumlah prediksi biaya secara sendiri - sendiri? Penyelesaian Jika dilihat dari model hubungan variabel tersebut di atas, maka kita dapat melakukan identifikasi sebagai berikut: Variabel biaya tetap dan biaya variabel merupakan variabel bebas atau independen dan juga disebut sebagai variabel predictor. Variabel jumlah prediksi biaya merupakan variabel tergantung atau dependen. Bulan merupakan label kasus yang dalam SPSS disebut sebagai Case Label Untuk menyelesaikan masalah ini kita akan menggunakan prosedur regresi linier berganda yang cocok dengan masalah dalam penelitian tersebut. Untuk menggunakan prosedur tersebut dalam SPSS kita memerlukan tahapan sebagai berikut Pengertian Regresi Linier Berganda Regresi linier berganda mempunyai makna sama dengan regresi linier sederhana hanya saja jumlah variabel bebas atau predictor lebih dari satu. Metode yang Tersedia dalam Regresi Linier Berganda Dalam SPSS disediakan dua metode utama, yaitu metode Enter dan metode Stepwise yang terdiri dari Stepwise, Forward dan Backward) yang digunakan untuk Regresi Linier Berganda. Metode Enter mempunyai pengertian semua variabel dikalkulasi berdasarkan kriteria (default) nya SPSS. Dalam regresi linier sederhana kita menggunakan metode Enter. Metode Stepwise mempunyai pengertian kalkulasi hubungan antara variabel – variabel bebas dengan variabel tergantung didasarkan pada sejauh mana variabel-variabel tersebut berkorelasi tinggi dengan variabel tergantung. Metode Forward dalam SPSS sama dengan Stepwise letak perbedaannya dalam metode Forward akan ada pembuangan (removal) variabel bebas yang kurang berdampak signifikan pada variabel tergantung; sedang metode Backward memprioritaskan penghitungan dengan didasarkan pada urutan signifikansi variabel – variabel bebas yang digunakan sebagai predictor. Variabel bebas yang memberi kontribusi paling signifikan akan didahulukan kemudian diikuti dengan variabel yang signfikan dan akhirnya kurang signfikan. Pemilihan metode ini hanya berlaku saat kita menggunakan variabel bebas lebih dari satu dalam regresi linier berganda. Pemilihan metode yang paling aman ialah metode Enter. Metode stepwise akan menghasilkan variabel- variabel bebas yang ada dalam model berkurang karena terkena proses penghilangan oleh program SPSS, yaitu variabel bebas yang kurang signifikan dampaknya terhadap variabel tergantung dalam model. Prosedur Regresi Linier Berganda dalam SPSS Untuk menggunakan prosedir regresi linier berganda dalam SPSS, langkahlangkahnya: Pertama: Aktifkan SPSS versi 23 Setelah SPSS aktif, masuk kedalam Data Editor dan pilih sub-menu di bagian kiri bawah Variabel View. Setelah itu buatlah desain variabel untuk kedua variabel yang kita pergunakan dalam penelitian dengan mengisikan informasi sesuai dengan Default Variable View pada kolom – kolom yang tersedia seperti pada contoh di bawah ini. Name Type Width Decimal Label Values Missing Column Align Measure Role bulan String 8 0 Bulan None None 8 R Nominal Input biayatetap numeric 8 2 Biaya Tetap None None 8 R Scale Input biayavariabel numeric 8 2 Biaya Variabel None None 8 R Scale Input jpb numeric 8 2 Jumlah None Prediksi Biaya None 8 R Scale Target Kedua: Masukkan data pada posisi Data View Untuk memasukkan data masuk ke perintah Data View, maka setelah itu masukkan data mulai dari data ke satu sampai dengan data ke 12 dari kiri atas ke bawah sebagaimana tampilan di bawah ini: bulan 1 . . 12 Biayatetap biayavariabel Jpb Ketiga: Melakukan analisis Melakukan analisis dengan regresi linier berganda dapat dilakukan dengan cara sebagai berikut: Klik Analyse > Regression: pilih Linear Pindahkan variabel jumlah prediksi biaya ke kolom Dependent Pindahkan variabel biaya tetap dan biaya variabel ke kolom Independent Masukkan variabel bulan ke kolom Case Labels Isi kolom Method dengan perintah Enter Klik Option: Pada pilihan Stepping Method Criteria masukkan angka 0,05 pada kolom Entry Cek Include constant in equation Pada pilihan Missing Values cek Exclude cases listwise > Tekan Continue Pilih Statistics: Pada pilihan Regression Coefficient pilih Estimate, Model Fit dan Descriptive. Pada pilihan Residual, kosongkan saja > Tekan Continue Klik Plots untuk membuat Grafik, pilih produce all partial plots > Klik Continue Klik OK untuk proses penghitungan Keempat: Menafsir hasil perhitungan Descriptive Statistics Jumlah Prediks i Biaya Biaya Tetap Biaya Variabel Mean 237.9167 52.0000 57.7500 Std. Deviation 18.76388 13.18401 10.85546 N 12 12 12 Bagian ini untuk digunakan untuk menafsir besarnya rata-rata jumlah prediksi biaya, biaya tetap dan biaya variabel. Rata-rata jumlah prediksi biaya ialah sebesar 237,9167 dan rata-rata biaya tetap sebesar 52,0000 dan rata-rata biaya variabel sebesar 57,7500 . Standard Deviasi jumlah prediksi biaya sebesar 18,76388 sedang untuk biaya tetap sebesar 13,18401 dan biaya variabel sebesar 10,85546 Bagian II Korelasi Correlations Pearson Correlation Sig. (1-tailed) N Jumlah Prediks i Biaya Biaya Tetap Biaya Variabel Jumlah Prediks i Biaya Biaya Tetap Biaya Variabel Jumlah Prediks i Biaya Biaya Tetap Biaya Variabel Jumlah Prediks i Biaya 1.000 .990 .997 . .000 .000 12 12 12 Biaya Tetap .990 1.000 .995 .000 . .000 12 12 12 Biaya Variabel .997 .995 1.000 .000 .000 . 12 12 12 Bagian ini untuk mengetahui ada dan tidaknya hubungan atau korelasi antara variabel jumlah prediksi biaya dan biaya tetap serta biaya variabel yang sama dengan saat kita mempelajari regresi linier sederhana di bagian sebelumnya. Besar hubungan antara variabel jumlah prediksi biaya dan biaya tetap ialah 0,990. Artinya hubungan kedua variabel tersebut sangat kuat. Korelasi positif menunjukkan bahwa hubungan antara jumlah prediksi biaya dan biaya tetap searah. Artinya jika biaya tetap besar, maka jumlah prediksi biaya akan meningkat juga. Besar hubungan antara variabel jumlah prediksi biaya dan biaya variabel ialah 0,997. Artinya hubungan kedua variabel sangat kuat. Korelasi positif menunjukkan bahwa hubungan jumlah prediksi biaya dan biaya variabel searah. Artinya jika biaya variabel besar, maka jumlah prediksi biaya akan meningkat pula. Hubungan antara variabel jumlah prediksi biaya dan biaya tetap signifikan jika dilihat dari angka signifikansi (sig) sebesar 0,000 yang lebih kecil dari 0,05. Jika angka signifikansi < dari 0.05 artinya ada hubungan yang signifikan antara kedua variabel tersebut. Hubungan antara variabel jumlah prediksi biaya dan biaya variabel signifikan jika dilihat dari angka signifikansi (sig) sebesar 0,000 yang lebih kecil dari 0,05. Jika angka signifikansi < dari 0.05 artinya ada hubungan yang signifikan antara kedua variabel tersebut. Bagian III Variabel yang Dimasukkan Variables Entered/Removedb Model 1 Variables Entered Biaya Variabel, Biaya a Tetap Variables Removed Method . Enter a. All requested variables entered. b. Dependent Variable: Jumlah Prediksi Biaya Bagian ini menunjukkan metode dalam memasukkan variabel Pada bagian ini terlihat kita memasukkan variabel “biaya tetap” dan “biaya variabel” serta tidak ada variabel yang kita keluarkan karena kita menggunakan metode “Enter” yang mempunyai makna kita memasukkan 2 variabel bebas secara bersamaan Bagian IV Ringkasan Model (Koefesien Determinasi) Model Summaryb Model 1 R .997a R Square .994 Adjusted R Square .993 Std. Error of the Estimate 1.56459 a. Predictors: (Constant), Biaya Variabel, Biaya Tetap b. Dependent Variable: Jumlah Prediks i Biaya Bagian ini menunjukkan besarnya koefesien determinasi yang berfungsi untuk mengetahui besarnya proporsi variasi variabel tergantung jumlah prediksi biaya yang dapat dijelaskan dengan menggunakan variabel bebas biaya tetap dan biaya variabel. Koefesien determinasi dapat juga digunakan untuk menghitung besarnya pengaruh kedua variabel bebas terhadap variabel tergantung jumlah prediksi biaya Angka R Square sebesar 0,994. Jika dijadikan sebagai Koefesien Diterminasi akan tersebut menjadi 0,994 dikalikan dengan 100% sama dengan 99,4%. Angka tersebut mempunyai pengertian bahwa sebesar 99,4% biaya produksi tidak langsung yang terjadi dapat dijelaskan dengan menggunakan variabel bebas jumlah tenaga kerja. Dengan bahasa umum kita dapat katakan bahwa variabel bebas jumlah tenaga kerja mempengaruhi variabel tergantung biaya produksi tidak langsung sebesar 99,4%. Sedang sisanya, yaitu 0,6% atau (100% - 99,4%) harus dijelaskan oleh faktor-faktor penyebab lainnya diluar model regresi ini. Besarnya Standar Error of the Estimate (SEE) ialah sebesar 1,56459 (untuk variabel jumlah prediksi biaya). Jika dibandingkan dengan angka Standar Deviasi (STD), sebesar 18,76388, maka angka SEE lebih kecil. Ini artinya nilai SEE menunjukkan secara tepat variabel – variabel bebas yang dijadikan sebagai prediktor dalam menentukan jumlah prediksi biaya. Angka yang baik untuk dijadikan sebagai penentu tepat atau tidaknya predictor harus lebih kecil dari angka standard deviasi.(SEE < STD) Bagian V Anova Bagian ini digunakan untuk melihat kelayakan model regresi dan disebut juga pengujian hipotesis secara simultan dengan menggunakan nilai F atau nilai signifikansi. ANOVAb Model 1 Regression Residual Total Sum of Squares 3850.885 22.032 3872.917 df Mean Square 2 1925.443 9 2.448 11 a. Predictors: (Constant), Biaya Variabel, Biaya Tetap b. Dependent Variable: Jumlah Prediksi Biaya F 786.554 Sig. .000a Dalam kasus ini kita menggunakan angka probabilitas atau signifikansi (sig) pada perhitungan Anova yang akan digunakan untuk uji kelayakan model regresi datau pengujian hipotesis secara simultan dengan ketentuan angka probabilitas yang baik untuk digunakan sebagai model regresi ialah harus lebih kecil dari 0,05. Uji ANOVA menghasilkan angka F sebesar 786,554 dengan tingkat signifikansi (angka probabilitas) sebesar 0,000. Karena angka probabilitas 0,000 < 0,05, maka model regresi ini layak untuk digunakan dalam memprediksi jumlah prediksi biaya. Dengan kata lain variabel biaya tetap dan biaya variabel secara bersama-sama mempengaruhi jumlah prediksi biaya. Untuk dapat digunakan sebagai model regresi yang layak dalam memprediksi variabel tergantung, maka angka signifikansi atau probabilitas harus < 0,05 Untuk melakukan pengujian kelayakan model regresi yang kita buat atau pengujian hipotesis secara simultan dengan data yang kita miliki, langkah – langkahnya sebagai berikut: Pengujian Hipotesis Secara Simultan dengan Uji F Seperti tertera pada keluaran di atas SPSS juga mengeluarkan nilai signfikansi (sig) selain nilai F yang dapat kita pergunakan sebagai alternatif lain untuk melakukan pengujian hipotesis dengan nilai F. Pertama: Membuat hipotesis H0: β=0 (Variabel biaya tetap dan biaya variabel tidak berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya produksi) H1: β≠ 0 (Setidak – tidaknya variabel biaya tetap atau biaya variabel berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya produksi) Kedua: Menghitung nilai F hitung (Fo) dengan rumus sebagai berikut Dari penghitungan SPSS diperoleh nilai Fo sebesar 786,554. Ketiga: Menggunakan kriteria sebagai berikut: Jika nilai F hitung (Fo) > F tabel (Fα); maka H0 ditolak dan H1 diterima Jika nilai F hitung (Fo) < F tabel (Fα); maka H0 diterima dan H1 ditolak Keempat: Menghitung nilai F tabel yang diperoleh dari Tabel Nilai F dengan ketentuan sebagai berikut: Nilai α sebesar 0,05 dan Degree of Freedom (DF) untuk numerator = jumlah variabel – 1 atau (k-1) dan denominator = jumlah data – jumlah variabel atau (n – k). Dengan demikian nilai F tabel untuk numerator adalah: 3 – 1 = 2 dan denominator adalah: 12 – 2 = 10; maka diperoleh nilai F dari tabel sebesar 4,10. Kelima: Mengambil keputusan Diperoleh dari hasil penghitungan nilai F hitung sebesar 786,554 > nilai F tabel sebesar 4,10 ; maka H0 ditolak dan H1 diterima. Artinya variabel biaya tetap atau biaya variabel berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya produksi. Pengujian dengan nilai F juga dapat dilakukan dengan cara menggunakan kurva sebagai berikut: H0 diterima Fα=4,10 Fo=786,554 Gambar kurva menunjukkan bahwa nilai Fo jatuh atau berada di daerah H0 ditolak oleh karena itu H1 diterima. Artinya variabel biaya tetap atau biaya variabel berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya produksi. Pengujian Hipotesis Secara Simultan dengan Signfikansi Pertama: Menentukan hipotesis H0: β=0 (Variabel biaya tetap dan biaya variabel tidak berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya produksi) H1: β ≠ 0 (Setidak-tidaknya variabel biaya tetap atau biaya variabel berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya produksi Kedua: Menggunakan kriteria pengambilan keputusan Kirteria pengambilan keputusan pengujian hipotesis sebagai berikut Jika nilai signifkansi atau probabilitas hitung < 0,05; maka H0 ditolak dan H1 diterima Jika nilai signifkansi atau probabilitas hitung > 0,05; maka H0 diterima dan H1 ditolak Ketiga: Mengambil keputusan Dari tabel keluaran di atas diketahui nilai signifikansi pada kolom Sig sebesar 0,000 < 0,05; maka H0 ditolak dan H1 diterima. Artinya variabel biaya tetap atau biaya variabel berpengaruh secara bersama-sama terhadap variabel jumlah prediksi biaya produksi secara signifikan. Dengan demikian model regresi yang kita buat sudah benar Bagian VI Koefisen Regresi Coefficientsa Model 1 (Constant) Biaya Tetap Biaya Variabel Unstandardized Coefficients B Std. Error 133.048 7.098 -.300 .372 2.086 .452 Standardized Coefficients Beta -.211 1.207 t 18.743 -.808 4.619 Sig. .000 .440 .001 a. Dependent Variable: Jumlah Prediksi Biaya Bagian ini menggambarkan persamaan regresi untuk mengetahui angka konstan, dan uji hipotesis signifikansi koefesien regresi secara parsial atau sendiri - sendiri: Persamaan regresinya: Y = a + b x1 x2 Y = 133,048 -0,300 X1 + 2,086 X2 Dimana: Y = Jumlah prediksi biaya X1 = Biaya tetap X2 = Biaya variabel Konstanta sebesar 133,048 mempunyai arti: Besarnya jumlah prediksi biaya saat X1 dan X2 sebesar 0. Dengan kata lain jika tidak ada biaya tetap dan biaya variabel, maka jumlah prediksi biaya akan sebesar 133,048 Koefisien regresi X1 sebesar -0,300 mempunyai arti bahwa setiap penambahan 1 unit biaya tetap (atau penambahan per 1 juta jika satuan dalam juta), maka jumlah prediksi biaya akan menurun sebesar -0,300 Koefisien regresi X2 sebesar 2,086 mempunyai arti bahwa setiap penambahan 1 unit biaya variabel , maka jumlah prediksi biaya akan meningkat sebesar 2,086 Pengujian Hipotesis dengan Uji t atau pengujian secara parsial Pada bagian berikut ini dilakukan pengujian hipotesis dengan Uji t secara parsial atau sendiri – sendiri untuk variabel bebas biaya tetap dan biaya variabel terhadap jumlah prediksi biaya Pengujian Hipotesis untuk Hubungan antara Variabel Biaya Tetap dengan Jumlah Prediksi Biaya Pengujian Hipotesis dengan Nilai t Pertama: Menentukan hipotesis H0: b=0 (Variabel biaya tetap tidak berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya) H1: b≠0 (Variabel biaya tetap berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya) Kedua: Menghitung nilai t hitung Dari penghitungan dengan menggunakan SPSS diperoleh nilai sebesar -,808 Ketiga: Menggunakan kriteria sebagai berikut: Jika nilai t hitung (to) > t tabel (tα); maka H0 ditolak dan H1 diterima Jika nilai t hitung (to) < t tabel (tα); maka H0 diterima dan H1 ditolak Keempat: Menghitung nilai t tabel yang diperoleh dari Tabel Nilai t dengan ketentuan sebagai berikut: Nilai α sebesar 0,05 dan Degree of Freedom (DF)= n -2. Karena pengujian dilakukan dengan dua sisi (yaitu b = 0 atau b ≠0); maka nilai α harus dibagi 2 dengan demikian nilainya menjadi α/2 = 0,05/2 hasilnya ialah 0,025. Ketentuan nilai t hitung menjadi α sebesar 0,025 dengan DF 12 – 2 = 10. Dari tabel t diketemukan sebesar 2,28. Kelima: Mengambil keputusan Karena nilai t negatif maka pengujian hipotesis dilakukan dengan menggunakan kurva seperti di bawah ini. Karena nilai t hitung (to) negatif, maka pengujian dilakukan disebelah kiri. Kita lihat bahwa nilai t hitung berada di daerah H0 diterima, maka H1 ditolak. Artinya variabel biaya tetap tidak berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya Pengujian Hipotesis dengan Nilai Signifikansi Pertama: Menentukan hipotesis H0: Variabel biaya tetap tidak berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya H1: Variabel biaya tetap berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya Kedua: Menggunakan kriteria pengambilan keputusan Kirteria pengambilan keputusan pengujian hipotesis sebagai berikut Jika nilai signifkansi atau probabilitas hitung < 0,05; maka H0 ditolak dan H1 diterima Jika nilai signifkansi atau probabilitas hitung > 0,05; maka H0 diterima dan H1 ditolak Ketiga: Mengambil keputusan Dari tabel keluaran di atas diketahui nilai signifikansi pada kolom Sig untuk variabel biaya tetap sebesar 0,440 > 0,05; maka H0 diterima dan H1 ditolak. Artinya variabel biaya tetap tidak berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya Pengujian Hipotesis untuk Hubungan antara Variabel Biaya Variabel dengan Jumlah Prediksi Biaya Pengujian Hipotesis dengan Nilai t Pertama: Menentukan hipotesis H0: b=0 (Variabel biaya variabel tidak berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya) H1: b≠0 (Variabel biaya variabel berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya) Kedua: Menghitung nilai t hitung Dari penghitungan dengan menggunakan SPSS diperoleh nilai sebesar 4,619 Ketiga: Menggunakan kriteria sebagai berikut: Jika nilai t hitung (to) > t tabel (tα); maka H0 ditolak dan H1 diterima Jika nilai t hitung (to) < t tabel (tα); maka H0 diterima dan H1 ditolak Keempat: Menghitung nilai t tabel yang diperoleh dari Tabel Nilai t dengan ketentuan sebagai berikut: Nilai α sebesar 0,05 dan Degree of Freedom (DF)= n -2. Karena pengujian dilakukan dengan dua sisi (yaitu b = 0 atau b ≠0); maka nilai α harus dibagi 2 dengan demikian nilainya menjadi α/2 = 0,05/2 hasilnya ialah 0,025. Ketentuan nilai t hitung menjadi α sebesar 0,025 dengan DF 12 – 2 = 10. Dari tabel t diketemukan sebesar 2,28. Kelima: Mengambil keputusan Diperoleh dari hasil penghitungan nilai t hitung sebesar 4,619 > nilai t tabel sebesar 2,28; maka H0 ditolak dan H1 diterima. Artinya variabel biaya variabel berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya. Pengujian dengan nilai t juga dapat dilakukan dengan cara menggunakan kurva sebagai berikut: Jika nilai t hitung (to) positif, maka pengujian dilakukan disebelah kanan. Pada kurva di atas kita melakukan pengujian hipotesis di sebelah kanan karena hasil nilai t hitung positif. Kita lihat bahwa nilai t hitung berada di daerah H0 ditolak, maka H1 diterima. Artinya variabel biaya variabel berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya Pengujian Hipotesis dengan Nilai Signifikansi •Pertama: Menentukan hipotesis H0: Variabel biaya variabel tidak berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya H1: Variabel biaya variabel berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya •Kedua: Menggunakan kriteria pengambilan keputusan Kirteria pengambilan keputusan pengujian hipotesis sebagai berikut Jika nilai signifkansi atau probabilitas hitung < 0,05; maka H0 ditolak dan H1 diterima Jika nilai signifkansi atau probabilitas hitung > 0,05; maka H0 diterima dan H1 ditolak •Ketiga: Mengambil keputusan Dari tabel keluaran di atas diketahui nilai signifikansi pada kolom Sig untuk variabel biaya variabel sebesar 0,001 < 0,05; maka H0 ditolak dan H1 diterima. Artinya variabel biaya variabel berpengaruh secara signifikan terhadap variabel jumlah prediksi biaya. Bagian VII: Statistic Residual Residuals Statistics a Predicted Value Residual Std. Predicted Value Std. Residual Minimum 207.4922 -2.06780 -1.626 -1.322 Maximum 268.4997 2.50785 1.635 1.603 Mean 237.9167 .00000 .000 .000 Std. Deviation 18.71044 1.41523 1.000 .905 N 12 12 12 12 a. Dependent Variable: Jumlah Prediksi Biaya Bagian ini memberikan penjelasan mengenai nilai minimum jumlah prediksi biaya yang diprediksi, yaitu sebesar: 207,4922; nilai maksimum jumlah prediksi biaya yang diprediksi sebesar: 268,4997; rata-rata jumlah prediksi biaya yang diprediksi sebesar 237,9167. Bagian VIII: Grafik Regresi Parsial untuk Variabel Biaya Tetap dan Jumlah Prediksi Biaya Partial Regression Plot Dependent Variable: Jumlah Prediksi Biaya 3 Januari Jumlah Prediksi Biaya Desember 2 November 1 April Mei Juni 0 Oktober Februari -1 Septembe Maret Agustus Juli -2 -3 -2 -1 0 Biaya Tetap 1 2 Jika kita melihat grafik di atas, maka akan terdapat sebaran data yang menuju kearah kanan atas dengan membentuk slope yang tidak sempurna, dengan adanya dua data yaitu Desember dan Januari tidak dalam posisi yang teratur. Dari grafik di atas tersebut kita dapat menyimpulkan bahwa biaya tetap mempengaruhi jumlah prediksi biaya secara tidak signifikan. Bagian IX: Grafik Regresi Parsial untuk Variabel Biaya Variabel dan Jumlah Prediksi Biaya Partial Regression Plot Dependent Variable: Jumlah Prediksi Biaya 8 Desember Jumlah Prediksi Biaya 6 4 Januari 2 Februari 0 November April Juni Oktober -2 Septembe Mei -1 Juli 0 Maret Agustus 1 Biaya Variabel 2 Jika kita melihat grafik di atas, maka akan terdapat sebaran data yang menuju kearah kanan atas dengan membentuk slope yang positif. Dari grafik di atas tersebut kita dapat menyimpulkan bahwa biaya variabel secara positif mempengaruhi jumlah prediksi biaya secara signifikan. Latihan: Perusahaan “A” ingin menganalisis pengaruh biaya bahan baku langsung dan biaya tenaga kerja langsung terhadap besarnya biaya variabel dengan menggunakan data di bawah ini jawablah pertanyaan-pertanyaan yang tersedia di bawah Minggu Satu Dua Tiga Empat Lima Enam Tujuh Delapan Sembilan Sepuluh Sebelas Duabelas Tigabelas Empatbelas Limabelas Biaya Variabel 215 153 138 176 244 128 167 99 311 99 81 69 71 179 101 Biaya Bahan Langsung 30 26 16 24 31 27 10 10 29 14 18 14 10 22 17 Baku Biaya Tenaga Langsung 25 20 14 16 30 24 12 13 19 15 13 12 8 19 14 Kerja Dengan menggunakan data di atas, jawablah pertanyaan di bawah ini: 1. Berapa besar korelasi antara biaya bahan baku langsung dengan biaya variabel? 2. Berapa besar korelasi antara biaya tenaga kerja langsung dengan biaya variabel? 3. Berapa besar korelasi antara biaya bahan baku langsung dan biaya tenaga kerja langsung dengan biaya varaibel? 4. Berapa besar pengaruh biaya bahan baku langsung dengan biaya variabel? 5. Berapa besar pengaruh biaya tenaga kerja langsung dengan biaya variabel? 6. Berapa besar pengaruh biaya bahan baku langsung dan biaya tenaga kerja langsung dengan biaya variabel? 7. Bandingkanlah hasil regresi antara satu variabel bebas dan satu variabel tergantung dengan dua variabel bebas dengan satu variabel tergantung. 8. Dengan menggunakan regresi sederhana, lakukan analisa untuk kasus 1 dan 2