Chapter I - Universitas Sumatera Utara
advertisement

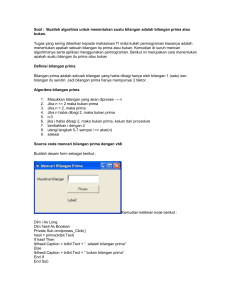
BAB 1 PENDAHULUAN 1.1 Latar Belakang Dengan berkembangnya Internet, banyak informasi tersedia dalam World Wide Web yang dapat diakses di seluruh negara. Pada saat pencarian informasi menggunakan search engine, jika query yang diberikan sebagai kata pencarian ditulis dalam bahasa tertentu, maka hasil pencarian yang diberikan kepada user hanya dokumen berisi informasi yang ditulis dalam bahasa tersebut. Sehingga hasil pencarian tidak dapat memberikan hasil yang maksimum untuk user. Berdasarkan informasi yang disediakan oleh web, maka informasi tersebut dapat menjadi bagian solusi dari permasalahan diatas untuk mendapatkan hasil pencarian yang maksimum baik dari query bahasa tertentu dan bahasa asing lainnya. Informasi merupakan kumpulan data yang akan diolah. Data dari informasi dapat menjadi data training untuk membangkitkan probabilistic translation model yang menerjemahkan query dari satu bahasa ke bahasa lain yang dapat digunakan untuk Cross Language Information Retrieval (CLIR) dan Machine Translation (MT). Pada MT sering ditemukan hasil terjemahan yang tidak tepat sehingga membuat user tidak mengerti hasil terjemahan secara keseluruhan. Hal ini juga menjadi sebuah permasalahan yang harus segera diatasi. Sedangkan pada CLIR, hasil pencarian hanya dokumen yang berisi informasi yang ditulis dalam query bahasa tertentu. Sehingga diperlukan probabilistic translation model untuk mendapatkan hasil terjemahan yang baik. Universitas Sumatera Utara Dari penelitian [9] dan [7], sebuah probabilistic translation model digunakan untuk menerjemahkan query dari bahasa asal ke bahasa tujuan. Dari kedua penelitian tersebut dapat dilihat bahwa probabilistic translation model dengan hasil terjemahan yang baik, dibutuhkan corpus berisi parallel text dalam jumlah besar sebagai data training. Untuk mendapatkan hasil terjemahan yang baik, diperlukan kaidah penerjemahan dari bahasa asal ke bahasa tujuan dan sebaliknya yang akan digunakan dalam probabilistic translation model. Corpus adalah kumpulan teks yang bisa digunakan untuk proses training dan pengembangan data [7]. Corpus berisi parallel text yang merupakan hasil text mining yang memperoleh pola berupa pasangan teks dari suatu bahasa terhadap bahasa lain di mana sumber yang dipakai berasal dari web. Berdasarkan latar belakang yang diuraikan sebelumnya, maka penulis berinisiatif untuk membuat sebuah corpus generator untuk mengumpulkan parallel text Bahasa Indonesia – Bahasa Inggris dalam jumlah besar, guna menjawab masalah yang telah diuraikan sebelumnya. 1.2 Manfaat dan Tujuan 1.2.1 Manfaat Penelitian Manfaat yang diperoleh dalam penelitian ini adalah parallel text yang dihasilkan dapat digunakan sebagai data training untuk menghasilkan probabilistic translation model yang menerjemahkan query dari satu bahasa ke bahasa lain yang disebut sebagai CLIR dan Machine Translation. Universitas Sumatera Utara 1.2.2 Tujuan Tujuan yang hendak dicapai dalam penelitian ini ialah membangun sebuah corpus generator berisi parallel text dalam bahasa Indonesia – bahasa Inggris. 1.2.3 Perumusan Masalah Dari latar belakang masalah yang diuraikan sebelumnya, maka dapat dirumuskan bahwa masalah yang melatar belakangi skripsi ini adalah bagaimana membangun sebuah sistem untuk menghasilkan parallel text yang berasal dari web. 1.2.4 Batasan Masalah Batasan masalah yang menjadi acuan dalam penelitian ini adalah: 1. Corpus generator yang dihasilkan adalah corpus berisi parallel text dengan sumber teks yang berasal dari web dwi bahasa. 2. Corpus yang dihasilkan adalah corpus dwibahasa berdasarkan kata dan kalimat dan berupa file text. 3. Metode yang digunakan untuk mendapatkan pasangan web page adalah berdasarkan nama web page. 4. Metode yang digunakan untuk mendapatkan parallel text adalah parallel text alignment berdasarkan kesamaan tag HTML. 5. Bahasa yang digunakan dalam pembuatan perangkat lunak ini menggunakan bahasa pemrograman PHP versi 5.0. Universitas Sumatera Utara 1.2.5 Sistematika Penulisan Pembahasan dalam skripsi ini secara garis besar dibagi dalam 5 (lima) bab, adapun susunan bab demi bab dalam skripsi ini adalah sebagai berikut: BAB 1 : Pendahuluan Bab ini menjelaskan mengenai latar belakang, perumusan masalah, identifikasi masalah, tujuan, manfaat, batasan masalah, serta sistematika penulisan. BAB 2 : Landasan Teori Bab ini menjelaskan teori-teori yang bersangkutan dengan masalah yang akan dibahas. Teori-teori tersebut yaitu membahas defenisi Sistem, Informasi, Analisis, Query, Search Engine, Hostname, URL, HTML, Text Mining, Corpus, Parallel Text, Cross Language Information Retrieval(CLIR), Machine Translation dan Probabilistic Translation Model. BAB 3 : Analisis dan Perancangan Sistem Bab ini membahas tentang bagaimana menganalisa permasalahan untuk mengambil parallel text antara bahasa Indonesia – bahasa Inggris dari web dan desain aplikasi interface yang dibangun serta proses-proses yang terdapat pada aplikasi (flow chart). BAB 4 : Implementasi dan Pengujian Sistem Bab ini menjelaskan bagaimana mengimplementasikan rancangan yang telah dibuat pada tahap analisis dan perancangan sistem ke dalam perangkat lunak komputer dengan menggunakan bahasa pemrograman PHP dan dilanjutkan menguji aplikasi yang telah dibangun. Universitas Sumatera Utara BAB 5 : Kesimpulan dan Saran Bab ini menguraikan kesimpulan dari penjelasan bab-bab sebelumnya, sehingga dari kesimpulan tersebut penulis mencoba memberi saran yang untuk melengkapi dan menyempurnakan pemgembangan Implementasi Corpus Generator dengan Parallel Text yang digunakan untuk masa yang akan datang. Universitas Sumatera Utara