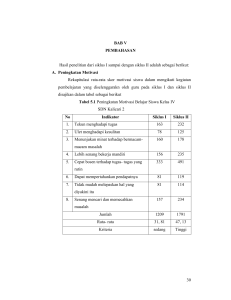
PERSAMAAN PERSEPSI PRAKTIKUM PENGOLAHAN DATA PERIKANAN 2018/2019 ACARA I STATISTIK DESKRIPTIF Tujuan: untuk memberikan rangkuman berbagai kumpulan data sesuai unitnya masing-masing, hanya memberikan informasi mengenai data yang dipunya dan sama sekali tidak menarik inferensia atau kesimpulan. Skala Nominal, digunakan untuk klasifikasi kualitatif atau kategorisasi, membedakan karakteristik satu dengan yang lain dengan memberikan symbol tidak dapat mengukur atau mengurutkan kategori. Contoh: gender, warna, bentuk, golongan darah, suku, agama, usia Skala ordinal, digunakan untuk mengurutkan peringkat dari data yang diamati. Memberikan gambaran tinggi rendah. Selain untuk membedakan karakteristik juga sudah menentukan arah peringkat. Contoh: Tingkat kesukaan makan ikan (1; sangat tidak suka 2: tidak suka 3:netral 4:suka 5: sangat suka) Skala interval, tidak hanya memungkinkan kita untuk mengklasifikasi, mengurutkan peringkat, tetapi juga bisa mengukur dan membandingkan ukuran perbedaan diantara nilai. Contoh: suhu, tingkat kecerdasan iq Skala rasio: hampir mirip dengan skala interval. memiliki titik nol mutlak, Contoh: waktu, panjang, berat dan tinggi. Dalam spss skala interval dan rasio digabung menjadi scale karena kedua data memiliki kemiripan. Variabel Kuantitatif Variabel diskret : variabel yang nilainya hanya terdiri dari bilangan bulat. Contoh: Jumlah penduduk, jumlah nelayan, jumlah anak dalam keluarga nelayan dan sebagainya. Variabel kontinu :variabel yang nilainya dapat berupa pecahan. Contoh: panjang ikan, berat ikan, volume air dan sebagainya. a. Statistik Deskriptif Input Data *Nilai Kuliah: SCALE *Lama belajar: SCALE *IPK: SCALE Analyze Deskriptive statistic Deskriptiv Deskriptive variable (Nilai Kuliah, Lama belajar, dan IPK) option (min, max, sd dan mean) Descriptive Statistics N Minimum Maximum Mean Std. Deviation Nilai 30 70.00 90.00 83.0000 7.49713 Lama 30 2.00 3.00 2.2667 .44978 IP 30 1.96 4.00 3.1213 .44504 Valid N (listwise) 30 N adalah Jumlah banyaknya sampel yang diamati Nilai minimum adalah nilai terkecil dari data yang diamati Nilai maksimum adalah nilai terbesar dari data yang diamati Rata-rata adalah nilai yang mampu menggambarkan suatu data yang digunakan Standar deviasi adalah nilai yang menunjukkan seberapa besar previsi data yang diamati. Previsi data adalah ketelitian b. Histogram Untuk melihat sebaran data Graph Legacy diolog Histogram Histogram nilai mata kuliah) 3 histogram berdasarkan variabel. Variabel (Nilai mata kuliah) Titles (Line 1 – Interpretasi: Berdasarkan histogram Nilai dengan jumlah data 30, rerata 83 dan standar deviasi sebesar 7,497 menunjukkan bahwa nilai 70 (rentang 66-75) diperoleh sejumlah 5 mahasiswa, nilai 80 (rentang 76-85) diperoleh sejumlah 11 mahasiswa, dan nilai 90 (rentang 86-95) diperoleh sejumlah 14 mahasiswa. Interpretasi: Berdasarkan histogram Lama Kuliah dengan jumlah data 30, rerata 2,27 tahun dan standar deviasi 0,45 menunjukkan bahwa yang memiliki lama kuliah 2 tahun sebanyak 22 orang, lama kuliah 3 tahun sebanyak 8 orang. Interpretasi: Berdasarkan histogram IP diketahui bahwa IP paling banyak diperoleh adalah pada rentang 2,5 – 3 sementara IP yang paling sedikit diperoleh adalah pada rentang 1,5 – 2. Jumlah data yang digunakan adalah 30, dengan rata-rata data 3,12 dan standar deviasi 0,445. Saran untuk deskripsi histogram yang baik: 1. Menyebutkan nama histogram. 2. Menyebutkan semua kelas jika jumlah kelas sedikit (1-3), jika jumlah kelas banyak (>3) boleh menyebutkan kelas dengan frekuensi tertinggi dan terendah. 3. Menyebutkan nilai kelas atau rentang kelas berdasarkan dengan informasi yang tertampil pada histogram. 4. Menyebutkan frekuensi secara rinci (bilangan bulat jika variabel diskrit) 5. Konsistensi (contoh: jumlah, rerata, standar deviasi: yaitu menggunakan rerata dan bukan mean) 6. Menggunakan kalimat yang baik dan benar (contoh menggunakan kata sebanyak atau sejumlah, dan tidak seperti ini: nilai 80 6 orang atau tidak baku seperti: 2 tahun ada 9 orang). 7. Menyebutkan satuan (orang, tahun, dll) c. Crosstab Fungsi crosstab untuk melihat kecenderungan data. Input data “Gender : NOMINAL “Pilihan : ORDINAL “Nilai mata kuliah: ORDINAL Analyze Deskriptive statistic Crosstabs Row (Nilai mata kuliah) Colums (Gender dan pilihan) ok Case Processing Summary Cases Valid N Missing Percent N Total Percent N Percent Nilai * Gender 30 100.0% 0 0.0% 30 100.0% Nilai * Pililhan 30 100.0% 0 0.0% 30 100.0% Nilai * Gender Crosstabulation Count Gender Pria Nilai Total Total Wanita C 3 2 5 B 1 10 11 A 2 12 14 6 24 30 Berdasarkan gender, jumlah mahasiswa yang memperoleh nilai A pada pria terdapat 2 orang sementara pada wanita terdapat 12 orang. Jumlah mahasiswa yang memperoleh nilai B pada pria terdapat 1 orang sementara pada wanita terdapat 10 orang. Jumlah mahasiswa memperoleh nilai C pada pria 3 orang sementara pada wanita terdapat 2 orang Jumlah total mahasiswa 30 orang. Nilai * Pililhan Crosstabulation Count Pililhan 1 Nilai Total Total 2 3 C 2 3 0 5 B 8 1 2 11 A 6 7 1 14 16 11 3 30 Pada tabel tabulasi silang dengan jumlah data 30, diketahui berdasarkan pilihan, jumlah mahasiswa yang memperoleh nilai A mata kuliah PIPK pada pilihan pertama terdapat 6 orang, pada pilihan kedua terdapat 7 orang, dan pada pilihan ketiga terdapat 1 orang. Jumlah mahasiswa yang memperoleh Nilai B mata kuliah PIPK pada pilihan pertama jurusan terdapat 8 orang, pada pilihan kedua terdapat 1 orang, dan pada pilihan ketiga terdapat 2 orang. Jumlah mahasiswa yang memperoleh Nilai C mata kuliah PIPK pada pilihan pertama jurusan terdapat 2 orang, pada pilihan kedua terdapat 3 orang, dan tidak terdapat pada pilihan ketiga. Saran untuk Deskripsi Tabulasi Silang yang Baik: 1. Menyebutkan jumlah total data yang digunakan. 2. Konsistensi (berdasarkan 1 aspek); konsistensi penyebutan (contoh salah: pertama, ke 2, dan ke-3) 3. Menggunakan kalimat yang baik dan benar (contoh menggunakan kata sebanyak atau sejumlah, dan tidak seperti ini: nilai 80 6 orang atau tidak baku seperti: 2 tahun ada 9 orang). 4. Menyebutkan satuan (orang, tahun, dll) 5. Tidak menyebutkan 0 orang (atau satuan lain)