1 BAB I PENDAHULUAN 1.1. LATAR BELAKANG Regresi linier
advertisement

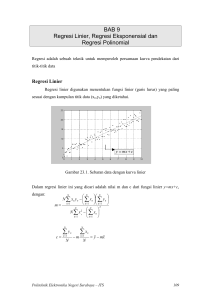
BAB I PENDAHULUAN 1.1. LATAR BELAKANG Regresi linier adalah teknik pemodelan di mana nilai variabel dependen dimodelkan sebagai kombinasi linier pada sekumpulan variabel penjelas. Variabel dependen merupakan variabel yang dijelaskan atau diestimasi oleh variabel penjelas. Sedangkan variabel penjelas merupakan variabel yang digunakan untuk mengestimasi variabel dependen. Regresi linier sederhana mengacu pada model regresi linier untuk satu variabel penjelas. Sedangkan, model regresi linier ganda merupakan perluasan dari model regresi linier sederhana yang memungkinkan variabel dependen dimodelkan untuk dua atau lebih variabel penjelas (Hayter, 2012: 543-608). Dalam pembuatan model regresi linier, tidak tertutup kemungkinan model awal yang diperoleh masih kurang optimal. Hal ini dilatar belakangi oleh 3 alasan. Alasan pertama adalah terjadinya overspecified, yaitu terlalu banyak variabel yang dimasukan ke dalam model. Alasan kedua, model tidak mengandung variabel yang tepat. Dan alasan ketiga, model tidak memiliki hubungan matematis yang benar (Freund, Wilson, and Sa, 2006: 227). Terdapat beberapa metode untuk menyeleksi variabel penjelas yang layak masuk dalam model sehingga diperoleh model terbaik. Salah satu diantaranya yaitu Best Subset Regression (Hanum, 2011). Best Subset Regression memulai pemilihan dengan model paling sederhana yaitu model dengan satu variabel. Selanjutnya dilanjutkan dengan variabel lain satu per satu sampai didapat model yang memenuhi kriteria terbaik. Terdapat beberapa 1 2 kriteria untuk mengevaluasi pemilihan model terbaik dalam Best Subset Regrression. Salah satu diantaranya dapat menggunakan statistik C-p Mallow (Hanum, 2011). Statistik C-p Mallow dikembangkan oleh Colin Mallows sebagai alat dalam mengestimasi jumlah variabel penjelas regresi. Statistik C-p Mallow membandingkan ketepatan dan bias dari model penuh dengan model subset terbaik dari jumlah variabel penjelas. Sebuah model dengan terlalu banyak variabel penjelas dapat menghasilkan model yang tidak tepat (Nirmalraj dan Malliga, 2011). Pada statistik C-p Mallow, model yang baik memiliki nilai statistik C-p Mallow mendekati jumlah parameter. Selain itu, diketahui juga model dengan nilai C-p Mallow yang kecil yang akan digunakan (Lindsey dan Sheather, 2010). Regresi linier menghasilkan model-model berdasarkan hasil analisis statistik yang dapat memberikan manfaat jika model yang benar telah dipilih dan asumsi lain yang mendasari model terpenuhi (Freund, Wilson, and Sa, 2006:119). Dalam model regresi linier terdapat asumsi klasik yang diperlukan untuk mendapatkan estimator Ordinary Least Squared (OLS) yang bersifat Best Linear Unbiased Estimator (BLUE). Terdapat empat asumsi klasik yang harus terpenuhi yaitu uji normalitas residual, uji autokorelasi residual, uji heteroskedastisitas residual dan uji multikolinearitas (Rosadi, 2011:71-75). Pada setiap uji asumsi, seringkali terjadi pelanggaran-pelanggaran. Pelanggaran pada uji normalitas yaitu residual tidak berdistribusi normal. Salah satu cara yang dilakukan untuk mengatasi residual yang tidak berdistribusi normal adalah dengan mentransformasikan variabel dependen ke dalam bentuk Logaritma Natural (Priatinah dan Kusuma, 2012). Pelanggaran terhadap uji heteroskedastisitas yaitu residual variance berubah-ubah. Salah satu metode estimasi parameter yang bisa mengatasi hal tersebut adalah metode regresi kuantil median (Uthami, Sukarsa, 3 Kencana, 2013). Pelanggaran terhadap uji autokorelasi residual yaitu terdapat autokorelasi pada residual variabel. Adanya autokorelasi menyebabkan estimasi yang dihasilkan masih tidak efisien. Dalam mengatasi autokorelasi terdapat beberapa cara yang dapat dilakukan, dua diantaranya yaitu menggunakan Generalized Least Square (GLS) dan Feasible Generalized Least Square (FGLS). GLS digunakan apabila koefisien autokorelasi diketahui, namun apabila koefisien autokorelasi tidak diketahui maka digunakan FGLS. Koefisien autokorelasi dapat diduga berdasarkan nilai Durbin Watson, nilai residual, atau cochrane orcutt iterative procedure. Pelanggaran selanjutnya yaitu adanya multikolinearitas yang menyebabkan nilai estimasi parameter model yang dihasilkan tidak stabil sehingga hal tersebut harus diatasi. Salah satu metode yang digunakan untuk mengatasi adanya kasus multikolinearitas adalah regresi ridge (Aeni, Sutikno, Djumali, 2012). Terdapat penelitian yang berhubungan dengan penelitian ini. Pada tahun 2013 terdapat penelitian tentang penerapan metode transformasi logaritma natural dan partial least squares untuk memperoleh model bebas multikolinearitas dan outlier. Kasus yang terjadi pada penelitian tersebut yaitu terdapat multikolinearitas dan outlier pada data tingkat penghunian kamar hotel di kota Kendari. Dengan menggunakan gabungan antara transformasi logaritma natural dan partial least squares diperoleh model yang bebas multikolinearitas dan outlier, dan model yang diperoleh masih mempunyai nilai R2 yang kecil (Ohyver, 2013). Pada tahun 2011 terdapat penelitian tentang faktor konsumsi bahan bakar yang dianalisis secara statistik dan menghasilkan model regresi yang optimal. Hasil analisis dari Best Subset Regression yaitu diperoleh lima variabel penjelas yang menunjukkan bahwa model memiliki nilai adjusted R2 yang tinggi serta nilai statistik C-p Mallow dan kuadrat residual (S2) terendah (Nirmalraj and Malliga, 2011). Pada tahun 2010, 4 terdapat penelitian mengenai pengaruh kualitas pelayanan, fasilitas dan lokasi terhadap keputusan menginap. Hasil penelitian ini menunjukkan bahwa variabelvariabel tersebut signifikan mempengaruhi keputusan tamu dalam menginap. Selain itu, sebesar 47,3% variabel keputusan menginap dapat dijelaskan melalui variabel penjelas. Sedangkan sisanya 52,7% dijelaskan oleh variabel lain diluar ketiga variabel yang digunakan dalam penelitian tersebut. Sulawesi Tenggara (Sultra) merupakan salah satu provinsi di Indonesia. Sultra ditetapkan sebagai daerah otonom berdasarkan Perpu No. 2 tahun 1964 Jungto UU No. 13 Tahun 1964. Pada awalnya terdiri atas empat kabupaten dan kini setelah pemekaran Sultra telah mempunyai sepuluh kabupaten dan dua kota, di mana ibukotanya terletak di kota Kendari. Salah satu komponen utama yang penting dalam pembangunan ekonomi nasional maupun regional dan merupakan bagian dari industri pariwisata yaitu jasa perhotelan. Jasa perhotelan mendapat perhatian khusus dari pemerintah karena selain merupakan salah satu sumber pendapatan, juga dapat menciptakan lapangan kerja baru untuk masyarakat (BPS Provinsi Sultra, 2011). Berdasarkan data yang terdapat di BPS, diperoleh jumlah sampel hotel di kota Kendari sebanyak 90 hotel dengan jumlah kamar 471 buah, dan jumlah tempat tidur 673 buah. Jumlah tamu yang berkunjung selama tahun 2010, sebanyak 157.537 orang. Banyaknya jumlah hotel yang terdapat di kota Kendari, membuat setiap perusahaan perhotelan tentu ingin menaikkan jumlah pengunjung hotel. Untuk itu, perusahaan perhotelan perlu mengetahui faktor-faktor yang mempengaruhi jumlah tamu hotel. Analisis data perhotelan kota Kendari tentu akan menjadi sumbangan untuk perusahaan perhotelan dalam hal meningkatkan jumlah tamu. Berdasarkan data, dicurigai terdapat korelasi tinggi antar variabel penjelas yang dapat menyebabkan 5 terjadinya multikolinearitas. Misalnya, variabel jumlah fasilitas dan tarif maksimal dimana semakin banyak jumlah fasilitas suatu hotel maka tarif maksimal hotel tersebut akan meningkat. Selain itu, semakin banyak jumlah kamar maka jumlah tenaga kerja akan semakin banyak juga. Terdapat beberapa cara yang dapat digunakan dalam mengatasi korelasi antar variabel penjelas. Salah satu diantaranya menggunakan regresi ridge. Seperti yang disebutkan sebelumnya, tidak menutup kemungkinan model yang diperoleh untuk mengetahui variabel-variabel yang mempengaruhi jumlah tamu tidak optimal. Hal ini yang melatarbelakangi penelitian tentang aplikasi pemilihan model terbaik menggunakan Best Subset Regression dan regresi ridge. 1.2. RUMUSAN MASALAH Dari latar belakang yang telah diuraikan sebelumnya, maka peneliti merumuskan masalah dalam penelitian ini, yaitu: 1.2.1. Variabel penjelas mana saja yang terpilih dengan menggunakan Best Subset Regression berdasarkan statistik C-p Mallow? 1.2.2. Apakah model yang diperoleh sudah dapat digunakan untuk mengestimasi jumlah tamu hotel di kota Kendari? 1.3. RUANG LINGKUP Agar penelitian tidak meluas dan menyimpang dari pembahasan maka perlu diberikan pembatasan masalah. Pembatasan masalahnya sebagai berikut: 1. Penulis membahas mengenai Best Subset Regression menggunakan statistik C-p Mallow. 2. Best Subset Regression menggunakan statistik C-p Mallow diperoleh untuk mendapatkan variabel yang mempengaruhi jumlah tamu di kota Kendari berdasarkan data dari Badan Pusat Statistik (BPS). 6 3. Penelitian ini hanya sampai pada pemodelan variabel. 4. Metode regresi ridge digunakan untuk mengatasi multikolinearitas pada data perhotelan di kota Kendari berdasarkan model yang diperoleh dari Best Subset Regression. 5. Aplikasi statistik yang digunakan pada penelitian ini menggunakan software R Language. 6. Untuk membantu mengimplementasikan teori dalam penelitian ini, maka penulis juga merancang sebuah aplikasi menggunakan bahasa pemograman Java. 1.4. TUJUAN DAN MANFAAT Penelitian ini bertujuan untuk: 1. Memperoleh variabel-variabel penjelas yang terpilih untuk pemodelan regresi. 2. Memperoleh model regresi yang dapat digunakan untuk mengestimasi jumlah tamu hotel di kota Kendari. Penelitian ini memiliki manfaat sebagai berikut: 1. Bagi pengelolah hotel : penelitian ini diharapkan dapat memberikan konstribusi dalam meningkatkan jumlah tamu. 2. Bagi peneliti lain : sebagai bahan referensi dalam menentukan model terbaik regresi.