Langkah Kerja Klasifikasi Dataset Glass Identification Database
advertisement

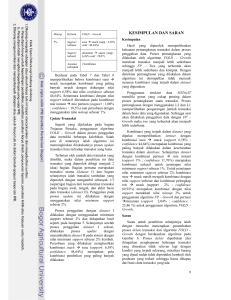
DATA MINING LANJUT Langkah Kerja Klasifikasi Dataset Glass Identification Database Menggunakan KNN (K-Nearest Neighbors) Praktikum Data Mining Lanjut Disusun Oleh: FITRA RIYANDA 1208107010079 JURUSAN INFORMATIKA FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SYIAH KUALA DARUSSALAM, BANDA ACEH APRIL, 2013 LANGKAH KERJA 1. Pengambilan Data Sampel Dataset Glass Identification Database diambil dari alamat http://archive.ics.uci.edu/ml/datasets/Glass+Identification. Dataset ini merupakan hasil analisa apakah suatu kaca dapat mengembang atau tidak. 2. Deklarasi Dataset Dalam format ARFF (Attribute‐Relation File Format) Dataset yang diperoleh dari dari UCI tersebut kemudian dirapikan dan dibuat sesuai format untuk pembentukan file ARFF yang akan di jalankan melalui aplikasi Weka. Untuk melakukan pembuatan format file tersebut, maka diperlukan suatu program yang dapat melakukan format ARFF secara otomatis sesuai dataset yang tertera. Gambar 1 Dataset Orisinil Pada UCI Gambar 2 ARFF Creator Untuk Merubah Format Text Ke ARFF Dari data yang telah diambil dari UCI kemudian dirubah formatnya dengan beberapa tahapan sesuai yang dibutuhkan sehingga tampak pada gambar berikut: Gambar 3 Hasil Output Format ARFF Tampak dari gambar 3.3 memperlihatkan format ARFF telah terbentuk dan siap untuk dijalankan pada Weka. a. Membagi Dataset Menjadi Trainingset dan Testingset Pada metode klasifikasi dataset menggunakan algoritma KNN dibutuhkan trainingset sebagai pembelajaran dan sebagai histori atau acuan untuk dataset yang ingin diuji dengan sample missing value. Uji coba dataset dilakukan dengan menentukan nilai k sebagai jarak data yang ingin diuji dengan pendekatan nilai tersebut sesuai dengan nilai k yang memiliki akurasi yang tinggi dan dengan testingset sebagai data sample-nya. Dari itu data trainingset dan testingset dibagi 70-75% sebagai trainingset dan 25-30% sebagai testingset dari jumlah data yang ada pada dataset tersebut. b. Menguji Akurasi Uji akurasi dataset dengan metode klasifikasi menggunakan KNN (KNearest Neighbor Classifier ) menggunakan Software Weka. Pada metode ini dilakukan pengambilan sampel dengan nilai akurasi diambil K=1, K=3, K=5, K=7, K=10 dan no distance weighting pada parameter distanceWeighting.



![[LEMBAR REVISI SIDANG TESIS] Fitri Ayuning Tyas P31.2018.02164](http://s1.studylibid.com/store/data/004382295_1-613372ba35b413d27c6f42fcca0c1c00-300x300.png)