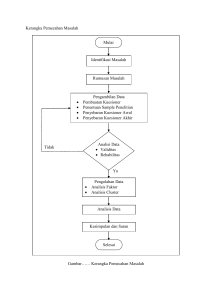
Volume 3 No 2 September 2023 DOI: https://doi.org/10.53514/jco.v3i2.394. e-ISSN 2776-9690 Pengolahan Data Pelanggan Dengan Tenik Clustering K-Means Di Aplikasi Weka Yanwaris Arisman Stenly Sikirit Jitroh Sesa Brian Hery Bosawer Kevin Julius Salenussa Universitas Muhammadiyah Sorong ABSTRAK p pelanggan me Setiap Pelanggan memiliki intensitas yang berbeda- beda dalam berbelanja. Beberapa ada yang berbelanja dengan jumlah banyak dan juga ada juga yang sedikit baik dari pelanggan yang berpendapatan tinggi maupun rendah.kita perlu melakukan analisis data agar bisa mengetahui kebiasaan dari para pelanggan dalam berbelanja. Oleh karena itu penulis melakukan analis datamining menggunakan data pelanggan. Dalam melakukan analisis penulis menggunakan alat bantu tools WEKA . Metode yang digunakan adalah metode k-means clustering dengan 5 cluster.Dengan Jumlah Sebagai berikut, C1 dengan 44 data, C2 dengan 43 data, C3 dengan 34 data, C4 dengan 35 data, C5 dengan 44 data. Kata Kunci: Pelanggan, Weka, Kmeans, Clustering, Data Mining I. Pendahuluan Karakter Pelanggan dalam berbelanja di sebuah toko atau pusat perbelanjaan tentu akan berbeda- beda. Hal ini dipengaruhi oleh faktor ekonomi.(Studi Pendidikan Ekonomi Koperasi & Muhson, n.d.) Dimana orang berpenghasilan rendah akan membelanjakan Sebagian besar atau keseluruhan uangnya di pasar tradisional dibanding di mall. dari fakta tersebut pihak toko harus mengetahui karakteristik pelanggannya (Budi, 2015) hal tersebut sangatlah penting karena banyak toko yang berujung bangkrut karena penyediaan barang yang dijual tidak sesuai dengan kebutuhan Sebagian besar pelanggan toko (Naim & Yahya, 2022) Berdasarkan hasil wawancara dengan salah satu pemilik toko, pak Ko Lim mengatakan, terkadang barang yang dijual tidak tepat sasaran karena kurangnya pemahaman data pelanggan, dan kebiasaan pelanggan yang tidak terprediksi. Maka penjualan menjadi tidak maksimal (Mardi, 2017). Harapannya pihak toko bisa melihat persentase pelanggan untuk penentuan karakter pelanggan, jika berhasil dan berdampak terhadap pengambilan keputusan toko dalam penyediaan barang, maka pengolahan data pelanggan dengan data miner akan direkomendasikan ke toko lainya (Susanto & Sudiyatno, 2014). Data mining merupakan proses dengan teknik statistik, kecerdasan buatan, matematika,dan machine learning untuk Ekstrak dan akses informasi yang berguna dan pengetahuan yang relevan dari database besar (Zulfa et al., 2020). Tujuan utama dari data mining adalah untuk mencari, mengeksplorasi atau mengekstraksi pengetahuan dari data atau informasi yang tersedia bagi kita. Clustering adalah proses yang mengidentifikasi kesamaan sifat dalam suatu kelompok untuk menghasilkan informasi yang berguna. Metode pengelompokan data telah banyak digunakan di berbagai bidang, misalnya dalam pemodelan, pengambilan keputusan dalam penambangan data, pengenalan pola, dan dalam bidang kesehatan. Ada banyak algoritma untuk melakukan proses integrasi pada kumpulan data yang besar. Pada penelitian ini, peneliti akan menggunakan algoritma K-Means untuk memilih jumlah cluster yang optimal. KMeans adalah algoritma yang banyak digunakan karena efisien dan efektif. Hal ini dikarenakan Kmeans mudah dipelajari dan waktu komputasinya relatif singkat (Dwiyanti & Habibi, 2024) II. Landasan Teori A. Clustering Clustering adalah suatu pemrosesan data dimana data dikelompokan menjadi beberapa kelompok sehingga objek dalam satu kelompok memiliki banyak kesamaan dan memiliki banyak perbedaan dengan objek dalam kelompok lain. Perbedaan dan persamaan seringkali didasarkan pada nilai properti objek dan dapat juga berupa perkiraan jarak. Clustering sendiri juga disebut klasifikasi tanpa pengawasan, karena clustering sebagian besar dipelajari dengan minat. Analisis cluster adalah proses membagi satu set objek data menjadi subset. Setiap subgrup merupakan satu grup, sehingga item-item dalam grup tersebut serupa, dan memiliki perbedaan dengan item-item dari grup lainnya. Klasifikasi tidak dilakukan oleh algoritma pengelompokan manual. Oleh karena itu, pengelompokan sangat berguna dan dapat mengidentifikasi kelompok yang tidak diketahui dalam data. Analisis cluster banyak digunakan dalam berbagai aplikasi seperti Business Alfin Falakhi | Pengolahan Data Pelanggan Dengan Tenik Clustering K-Means Di Aplikasi Weka 54 Volume 3 No 2 September 2023 DOI: https://doi.org/10.53514/jco.v3i2.394. e-ISSN 2776-9690 Intelligence, Pengenalan Pola Gambar, Pencarian Web, Biologi, dan Keamanan. Dalam intelijen bisnis, pengelompokan dapat mengatur banyak pelanggan menjadi banyak kelompok. Misalnya, mengelompokkan pelanggan ke dalam beberapa kelompok dengan karakteristik kuat yang serupa(Choudhary & Saxena, 2023). Clustering juga dikenal sebagai partisi data, karena clustering mengelompokkan banyak kumpulan data berdasarkan kesamaan. Clustering juga dapat digunakan sebagai deteksi outlier, dimana outlier mungkin lebih menarik daripada kasus normal. Sistem tersebut adalah Outlier Detection, mendeteksi penipuan kartu dan melacak aktivitas kriminal di e-commerce. Contohnya adalah pengecualian dalam transaksi kartu kredit. (Fauzan & Alfian, 2024) B. K-means Teknik Pengelompokan K-Means adalah teknik pengelompokan sederhana tanpa pengawasan. Misalkan D adalah dataset dari n objek, dan k adalah jumlah grup yang akan dibuat, algoritma klasifikasi mengatur objek menjadi k bagian (k ≤ n), dengan setiap bagian mewakili grup. Setiap klaster dirancang untuk mengoptimalkan kriteria klasifikasi, seperti fungsi keragaman versus jarak, sehingga objek dalam klaster serupa, dan objek dalam klaster berbeda berbeda dalam hal fitur dataset. Persamaan untuk menghitung jarak antar data pada K-Means menggunakan rumus Euclidean Distance (D) yang tertera pada rumus tersebut. (Herdiana et al., 2025) III. Metode Penelitian A. Tahapan Penelitian Proses penelitian adalah langkah-langkah yang dilakukan selama penelitian (Irmayani, 2021). Proses survei dirancang untuk memfasilitasi akses ke hasil survei, untuk menyelesaikan survei secara tepat waktu dan untuk melaksanakan survei seperti yang diharapkan. Algoritma pencarian yang digunakan dapat dilihat pada gambar dibawah ini: Gambar 1 Kerangka kerja penelitian Gambar tersebut menunjukkan alur tahapan dalam proses pengolahan data menggunakan teknik clustering KMeans yang disusun secara sistematis. Proses dimulai dengan identifikasi masalah, yaitu menentukan fokus utama dan tujuan dari analisis data, misalnya untuk segmentasi pelanggan. Setelah itu, dilakukan studi literatur guna memahami teori-teori dan penelitian terdahulu yang relevan dengan teknik clustering dan algoritma K-Means. Tahap selanjutnya adalah pengumpulan data, yakni mengumpulkan data yang sesuai dan dibutuhkan dari berbagai sumber.(Herdiana et al., 2025) 1) Identifikasi Masalah • Mengetahui data pelanggan dari berbagai kelas ekonomi • Pengolahan data yang buruk menjadi faktor utama penyebab terjadinya pengabilan keputusan yang kurang tepat oleh perusahaan • Data pelanggan menjadi hal yang penting untuk menjadi pertimbangan perusahaan dalam pengambilan keputusan • Mengolah data smemerlukan metode inovatif supaya memudahkan dalam pemrosesan data dan data yang di hasilkan akurat. 2) Pengumpulan data • Metode Pengumpulan Data Alfin Falakhi | Pengolahan Data Pelanggan Dengan Tenik Clustering K-Means Di Aplikasi Weka 55 Volume 3 No 2 September 2023 DOI: https://doi.org/10.53514/jco.v3i2.394. e-ISSN 2776-9690 Metode pengumpulan adalah cara atau proses yang dilakukan untuk mengumpulkan data. Dalam penelitian pengumpulan data diperlukan untuk mencapai tujuan penelitian. Pada Jurnal ini penulis melakukan penelitian pada data pelanggan mall. 3 cara berikut merupakan cara yang digunakan : 1. Observasi Observasi atau pengamatan adalah Suatu metode pengumpulan data yang dilakukan dengan pengamatan secara langsung, serta melihat dan mengambil data dari tempat penelitian tersebut 2. Wawancara Teknik pengumpulan data yang dilakukan dengan cara tanya jawab. 3. Dokumentasi Dokumentasi adalah teknik pengumpulan data dengan melihat langsung sumber-sumber dokumen yang terkait baik tertulis maupun elektronik. • Sumber Data Sumber data dalam penelitian secara umum terbagi menjadi dua, yaitu data primer dan data sekunder. Data primer merupakan data yang dikumpulkan langsung oleh peneliti dari sumber pertama melalui berbagai metode seperti wawancara, observasi, survei, kuesioner, atau eksperimen. Data ini bersifat orisinal dan dikumpulkan khusus untuk menjawab permasalahan dalam penelitian yang sedang dilakukan. Karena dikumpulkan langsung dari responden atau objek penelitian, data primer cenderung lebih akurat dan relevan dengan tujuan penelitian. Namun, pengumpulan data primer biasanya memerlukan waktu, biaya, dan tenaga yang lebih besar serta harus dilakukan secara hati-hati agar tidak menimbulkan bias.(Ahsina et al., 2022) Sementara itu, data sekunder adalah data yang diperoleh dari sumber-sumber yang sudah ada, baik yang telah dipublikasikan maupun tidak. Data ini dapat berasal dari instansi pemerintah, lembaga riset, perusahaan, jurnal ilmiah, atau repositori publik seperti Kaggle. Berbeda dengan data primer, data sekunder tidak dikumpulkan secara langsung oleh peneliti, melainkan digunakan kembali dari penelitian atau dokumentasi yang sudah tersedia. Kelebihan data sekunder terletak pada kemudahannya diakses serta efisiensi waktu dan biaya. Namun, kelemahannya adalah tidak selalu sesuai dengan kebutuhan spesifik penelitian dan validitasnya tergantung pada keakuratan data yang dikumpulkan oleh pihak lain.(Wiguno & Nataliani, 2022) 3) Pemrosesan data Data yang telah diperoleh dalam penelitian ini akan diolah menggunakan aplikasi WEKA (Waikato Environment for Knowledge Analysis) melalui beberapa tahapan proses yang terstruktur. Tahap pertama adalah data selection, yaitu proses pemilihan atribut atau variabel yang relevan dari seluruh data yang tersedia. Pemilihan ini penting agar hanya fitur-fitur yang mendukung tujuan analisis yang digunakan dalam proses selanjutnya. Setelah itu, dilakukan tahap pre-processing, yakni pembersihan data dari kesalahan, duplikasi, nilai kosong, atau inkonsistensi yang dapat memengaruhi kualitas hasil analisis(Shital Patel et al., 2024). Langkah berikutnya adalah transformation, yaitu mengubah data ke dalam format atau skala yang sesuai, seperti melakukan normalisasi agar data berada dalam rentang yang sebanding untuk mempermudah proses perhitungan jarak pada algoritma clustering. Terakhir, dilakukan tahap clustering menggunakan algoritma K-Means, di mana data akan dikelompokkan ke dalam beberapa klaster berdasarkan kemiripan karakteristik antar data. Proses ini memungkinkan peneliti mengidentifikasi pola tersembunyi dan mengelompokkan data pelanggan secara lebih terstruktur untuk keperluan analisis lebih lanjut.(Tendra et al., 2021) B. Data Metode pengumpulan data yang dipakai adalah metode dokumentasi. pengumpulan data dilakukan dengan pemgbilan data yamg sudah ada dan tercatat dalam database pelanggan mall Selanjutnya data dirubah menjadi numerik supaya bisa diolah menggunakan aplikasi WEKA . (Manek et al., 2018) IV. Hasil Dan Pembahasan A. Hasil WEKA merupakan aplikasi pengolahan data yang sangat berguna dan memudahkan dengan berbagai tools,untuk melihat hasilnya kita perhatikan Langkah langkah berikut. (Sari et al., 2022) Alfin Falakhi | Pengolahan Data Pelanggan Dengan Tenik Clustering K-Means Di Aplikasi Weka 56 Volume 3 No 2 September 2023 DOI: https://doi.org/10.53514/jco.v3i2.394. e-ISSN 2776-9690 1) Persiapkan data set Dataset yang digunakan bernama Data_Client.csv.arff. dataset adalah data yang telah dikumpulkan dengan format csv tapi sudah di ubah menjadi format arff , berikut dibawah ini terdapat gambar dari persiapan dataset: Gambar 2 Buka dataset di weka Gambar tersebut menampilkan jendela dialog "Open File" dari aplikasi WEKA, yang digunakan untuk memilih dan membuka file dataset yang akan dianalisis. Dalam tampilan ini, pengguna sedang berada di direktori Downloads, dan terdapat beberapa file yang ditampilkan dalam daftar.(Awalina & Rahayu, 2023) File yang dipilih adalah "Data_Custom.arff", yang merupakan file dataset dengan ekstensi .arff (Attribute-Relation File Format). Format ARFF adalah format file yang umum digunakan oleh WEKA, berisi data dan deskripsi atribut yang digunakan dalam proses machine learning. Di bagian bawah jendela terlihat bahwa jenis file yang sedang dicari adalah *.arff, yang menunjukkan bahwa WEKA sedang difokuskan untuk membuka file dengan format tersebut.(Imanuel & Alfian, 2025) Gambar 3 Tampilan data set di weka Untuk melakukan klustering Klik tab cluster lalu pilih opsi simplekmeans. Gambar tersebut menunjukkan tampilan antarmuka utama WEKA Explorer pada tab Preprocess, yang digunakan untuk memuat dan meninjau dataset sebelum dilakukan analisis lebih lanjut. Dalam gambar ini terlihat bahwa sebuah file dataset bernama "Data_Custom.arff" telah berhasil dimuat ke dalam aplikasi. Informasi umum mengenai dataset ditampilkan di bagian atas layar, seperti jumlah instance (baris data) dan jumlah atribut (fitur) yang tersedia. Di panel sebelah kiri, terdapat daftar atribut yang ada dalam dataset, seperti CustomerID, Age, dan Balance Income, yang masing-masing dapat dipilih untuk dilihat detail statistiknya.(Mardiana & Nyoto, 2015) Alfin Falakhi | Pengolahan Data Pelanggan Dengan Tenik Clustering K-Means Di Aplikasi Weka 57 Volume 3 No 2 September 2023 DOI: https://doi.org/10.53514/jco.v3i2.394. e-ISSN 2776-9690 Gambar 4 .tab cluster Klik 2 kali pada tulisan simplekmeans untuk mengatur jumlah cluster dengan mengganti pada kolom cluster num (Aryanto et al., 2024) Gambar 5 mengatur jumlah cluster Gambar 6 Hasil clustering Untuk visualisasi data kita klik bagian algoritma yang kita pakai yaitu simplekmeans dibagian kiri bawah lalu klik visualize cluster assignments (Prasetyo et al., 2023) Alfin Falakhi | Pengolahan Data Pelanggan Dengan Tenik Clustering K-Means Di Aplikasi Weka 58 Volume 3 No 2 September 2023 DOI: https://doi.org/10.53514/jco.v3i2.394. e-ISSN 2776-9690 Gambar 7 Opsi visualisasi Pilih sumbu x = annual income pilih sumbu y = spending score .tujuan nya adalah untuk mengvisualisasi ke 5 cluster dengan karakter masing masing cluster berdasarka sumbu x dan y. (Annas & Wahab, 2023) Gambar 8 Sumbu X dan Y 1. Cluster 0 (biru): penghasilan tinggi tetapi Pembelanjaan lebih sedikit Cluster 1 (merah): Rata dalam hal Penghasilan dan Pembelanjaan Cluster 2 (hijau): Penghasilan tinggi dan juga Pembelanjaan banyak Cluster 3 (toska): Penghasilan lebih sedikit tetapi Pembelanjaan lebih banyak Cluster 4 (ungu): penghasilan lebih sedikit, Pembelanjaan lebih sedikit (Schubert, 2023) Gambar 9 Hasil visualisasi B. Pembahasan Data Mining dengan metode k-means mampu dengan baik mengklastering 200 pelanggan yang tedapat pada dataset Data_client Yaitu dengan melakukan clustering dibagi menjadi 5 label antara lain, adalah : Cluster 0 (biru): penghasilan tinggi tetapi Pembelanjaan lebih sedikit(44%) (Онищук et al., 2025) Alfin Falakhi | Pengolahan Data Pelanggan Dengan Tenik Clustering K-Means Di Aplikasi Weka 59 Volume 3 No 2 September 2023 DOI: https://doi.org/10.53514/jco.v3i2.394. e-ISSN 2776-9690 Cluster 1 (merah): Rata dalam hal Penghasilan dan Pembelanjaan(43%) Cluster 2 (hijau): Penghasilan tinggi dan juga Pembelanjaan banyak (34%) Cluster 3 (toska): Penghasilan lebih sedikit tetapi Pembelanjaan lebih banyak(35%) Cluster 4 (ungu): penghasilan lebih sedikit, Pembelanjaan lebih sedikit(44%) V. Kesimpulan Dengan menggunakan aplikasi WEKA memudahkan peneliti dalam mengolah data, sehingga data pelanggan dapat diproses dengan baik menggunakan metode clustering K-mens dengan baik dan akurat. Dengan ini data yang sudah diolah bisa menjadi pertimbangan bagi perusahaan untuk menentukan kebijakan dan pengambilan keputusan. (Gerian & Nataliani, 2023) Daftar Pustaka Ahsina, N., Fatimah, F., & Rachmawati, F. (2022). Analisis Segmentasi Pelanggan Bank Berdasarkan Pengambilan Kredit Dengan Menggunakan Metode K-Means Clustering. Jurnal Ilmiah Teknologi Infomasi Terapan, 8(3). https://doi.org/10.33197/jitter.vol8.iss3.2022.883 Annas, M., & Wahab, S. N. (2023). Data Mining Methods: K-Means Clustering Algorithms. International Journal of Cyber and IT Service Management, 3(1), 40–47. https://iiast.iaicpublisher.org/ijcitsm/index.php/IJCITSM/article/view/122 Aryanto, R. P., Nilogiri, A., & Wardoyo, A. E. (2024). Klasterisasi Jumlah Penduduk Provinsi Jawa Timur Tahun 20212023 Menggunakan Algoritma K-Means. JISKA (Jurnal Informatika Sunan Kalijaga), 9(2), 134–146. https://doi.org/10.14421/jiska.2024.9.2.134-146 Awalina, E. F. L., & Rahayu, W. I. (2023). Optimalisasi Strategi Pemasaran dengan Segmentasi Pelanggan Menggunakan Penerapan K-Means Clustering pada Transaksi Online Retail. Jurnal Teknologi Dan Informasi, 13(2), 122–137. https://doi.org/10.34010/jati.v13i2.10090 Choudhary, B., & Saxena, V. (2023). K-Means Clustering of Cloud Data using Weka and R Language. International Journal of Computer Applications, 184(49), 33–39. https://doi.org/10.5120/ijca2023922613 Dwiyanti, Z. A., & Habibi, R. (2024). Penerapan Algoritma K-Means untuk Mengukur Efektivitas Media Informasi dan Kepuasan Pelanggan. Jurnal Tekno Insentif, 18(2), 119–129. https://doi.org/10.36787/jti.v18i2.1689 Fauzan, R. M., & Alfian, G. (2024). Segmentasi Pelanggan E-Commerce Menggunakan Fitur Recency, Frequency, Monetary (RFM) dan Algoritma Klasterisasi K-Means. JISKA (Jurnal Informatika Sunan Kalijaga), 9(3), 170–177. https://doi.org/10.14421/jiska.2024.9.3.170-177 Gerian, M., & Nataliani, Y. (2023). Analisis Loyalitas Customer Perusahaan Konveksi dengan Model RFM dan Algoritma k-Means. Jurnal Transformatika, 21(1). https://doi.org/10.26623/transformatika.v21i2.7248 Herdiana, I., Kamal, M. A., Triyani, Estri, M. N., & Renny. (2025). A More Precise Elbow Method for Optimum K-means Clustering. 1–22. http://arxiv.org/abs/2502.00851 Imanuel, D. A., & Alfian, G. (2025). Visualisasi Segmentasi Pelanggan Berdasarkan Atribut RFM Menggunakan Algoritma K-Means Untuk Memahami Karakteristik Pelanggan pada Toko Retail Online. Jurnal Teknologi Informasi Dan Ilmu Komputer, 12(2), 283–292. https://doi.org/10.25126/jtiik.2025128619 Manek, F. I., Faisal, S., & Priyatna, B. (2018). Penerapan K-Means Clustering untuk Mengelompokkan Pelanggan Berdasarkan Data Penjualan Ayam. Techno Xplore : Jurnal Ilmu Komputer Dan Teknologi Informasi, 3(2), 88–93. https://doi.org/10.36805/technoxplore.v3i2.820 Mardiana, T., & Nyoto, R. D. (2015). Kluster Bag of Word Menggunakan Weka. Jurnal Edukasi Dan Penelitian Informatika (JEPIN), 1(1), 1–5. https://doi.org/10.26418/jp.v1i1.10145 Naim, Y., & Yahya, A. (2022). Implementasi Metode K-Means Dalam Penyebaran Pelanggan Koran Fajar Berbasis Webgis. Jurnal Ilmiah Sistem Informasi Dan Teknik Informatika (JISTI), 5(2), 25–32. https://doi.org/10.57093/jisti.v5i2.124 Prasetyo, A. N. B., Maimunah, M., & Sukmasetya, P. (2023). K-Means Clustering Method for Determining Waste Transportation Routes to Landfill. Jurnal Riset Informatika, 5(3), 277–284. https://doi.org/10.34288/jri.v5i3.219 Sari, R. A., Seta, H. B., & Diyasa, I. G. S. M. (2022). Implementasi K-Means Clustering dengan Menggunakan Data Transaksi Penjualan untuk Penentuan Reward pada Agen Aqua dan Gas LPG FF Tirta. Informatik : Jurnal Ilmu Komputer, 18(3), 293. https://doi.org/10.52958/iftk.v18i3.4673 Schubert, E. (2023). Stop using the elbow criterion for k-means and how to choose the number of clusters instead. ACM SIGKDD Explorations Newsletter, 25(1), 36–42. https://doi.org/10.1145/3606274.3606278 Shital Patel, Pooja Pancholi, & Arpita Chaudhury. (2024). Performance Analysis and Evaluation of Clustering Algorithms using WEKA. International Journal of Scientific Research in Computer Science, Engineering and Information Technology, 10(2), 677–684. https://doi.org/10.32628/cseit2410251 Tendra, G., Putra, J. R. K., & Johan, R. (2021). Implementasi Algoritma K-Means Clustering Pada Aplikasi Mobile Banking Bank Sampah Keluarahan Tuah Madani Kota Pekanbaru. Jurnal Komputer Dan Informatika, 9(2), 235– 243. https://doi.org/10.35508/jicon.v9i2.5142 Wiguno, T. C., & Nataliani, Y. (2022). Penerapan k-Means Clustering Berdasarkan Analisis RFM Terhadap Segmentasi Pembeli untuk Meningkatkan Strategi CRM. Jurnal Media Informatika Budidarma, 6(4), 1871. Alfin Falakhi | Pengolahan Data Pelanggan Dengan Tenik Clustering K-Means Di Aplikasi Weka 60 Volume 3 No 2 September 2023 DOI: https://doi.org/10.53514/jco.v3i2.394. e-ISSN 2776-9690 https://doi.org/10.30865/mib.v6i4.4472 Онищук, В., СТЕЛЬМАЩУК, С., & СКОЧИЛЯС, А. (2025). До Визначення Стійкості Автомобіля Категорії М1 З Причепом Категорії О2 У Гальмівному Режимі. Сучасні Технології В Машинобудуванні Та Транспорті, 1(24), 327–335. https://doi.org/10.36910/automash.v1i24.1739 Alfin Falakhi | Pengolahan Data Pelanggan Dengan Tenik Clustering K-Means Di Aplikasi Weka 61